さくらインターネット研究所の鶴田(@tsurubee3)です。先日、研究活動の一環として、時系列データ分析とData-centric AIの二つの視点から、大規模言語モデル(以下、LLM)の最新の研究動向について調査し、私の個人ブログに以下の二つの記事を書きました。本記事では、調査の動機とそれぞれの研究動向の概要について紹介します。
調査の動機
LLMは、自然言語処理の分野で革命的な進歩を遂げ、現在も驚異的な速さで発展を続けています。2022年末のChatGPTの登場がターニングポイントとなり、LLMの潜在能力が世間一般に広く認知されるようになりました。現在では、LLMは医療、法律、教育など多岐にわたる分野で革新的な応用が始まっており、産業界や学術界に大きな影響を与えています。さくらインターネット研究所では、さくらインターネット研究所 研究開発グループの取り組み紹介(24年4月)で紹介した通り、分散コンピューティング基盤やセキュアコンテナ、SRE (Site Reliability Engineering)などのITインフラ領域からマテリアルズ・インフォマティクス、AI創薬、さらには教育学など非常に幅広い分野の研究を行っています。どの分野の研究においても、すでにLLMの活用は始まっており、その影響力と可能性は今や無視できないものとなっています。このような背景から、最近では研究活動の一環として、継続的にLLMの研究動向の調査を行っています。
また今回は、LLMの研究動向を時系列データとData-centric AIの二つの切り口から調査しました。一つ目の時系列データとは、時間の推移とともに観測されるデータのことで、様々な実世界の分野で広く利用されています。例えば、さくらインターネット研究所ではクラウドのシステム障害診断を自動化する研究を行っており、この研究では時系列データである監視メトリクス(CPU使用率、メモリ使用量など)を取り扱っています。このような研究への応用も視野に入れて、時系列データ分析に対するLLMの活用について調査しました。二つ目のData-centric AIは、2021年のAndrew Ng先生の講演「MLOps: From Model-centric to Data-centric AI」の中で提唱されたAI研究をデータを中心として考える概念です。これまでのAI研究では、モデルの設計を改善することに重点が置かれてきましたが、最近ではデータの量や品質、信頼性を確保することの重要性がより強く認識されはじめています。このような背景から、データを中心として考えたLLMの課題や研究動向について調査しました。
LLM × 時系列データ分析
LLMの急速な進化は、自然言語の領域を超えて、より広範なデータモダリティへのLLMの適用可能性を探る研究への発展を促しており、その代表格が時系列データです。大変興味深いことに、最近の研究では、数値的な時系列データをテキストデータとして取り扱い、LLMにプロンプトとして直接入力するだけで、既存の時系列モデルの性能に匹敵するレベルで時系列予測ができることが報告されています。このような、一般的な時系列予測問題を自然言語生成の形式で取り扱った先駆的な研究として、PromptCastがあります。PromptCastは、気温予測、エネルギー消費予測、および顧客フロー予測の3つの実世界の予測シナリオが含まれているデータセットを用いたベンチマークの結果、時系列予測において従来の数値ベースの手法に匹敵する性能を達成し、特にzero-shot予測の設定で優れた汎化性能を持つことが報告されました。
また、最近の注目すべき研究は、数値的な時系列データのトークン化の方法に着目しています。LLMTimeは、Byte Pair Encoding (BPE)を用いたトークン化では、異なる浮動小数点数間でトークン化に一貫性がないことを指摘しており、各数字に異なるトークンが割り当てられるように数字の間にスペースを入れることを提案しました。その結果、GPT-3やLLaMA-2などの既存のLLMが、ダウンストリームタスクで学習した時系列モデルの性能に匹敵するか上回るレベルで、zero-shotで時系列予測ができることを報告しました。以上のようにPromptCastやLLMTimeは、ファインチューニングを行うことなくzero-shotで時系列予測ができるため、手元に学習データがない場合や少ない場合にも適用できる点で優れたアプローチです。
一方、十分な学習データを用意できる場合は、ファインチューニングを行うアプローチも有効です。例えば、[Zhou+, 2023] は、大規模なデータで事前学習した言語モデルを時系列データ分析に適用するために、下図のようにtransformerブロックのself-attentionおよびfeedforward層の重みを固定した事前学習済みモデルをファインチューニングする手法を提案しました。本手法は、時系列分類や異常検出を含む7つの主要な時系列分析タスクにおいて、最先端のベースラインモデルと同等か、それ以上の性能を達成したことを報告しました。
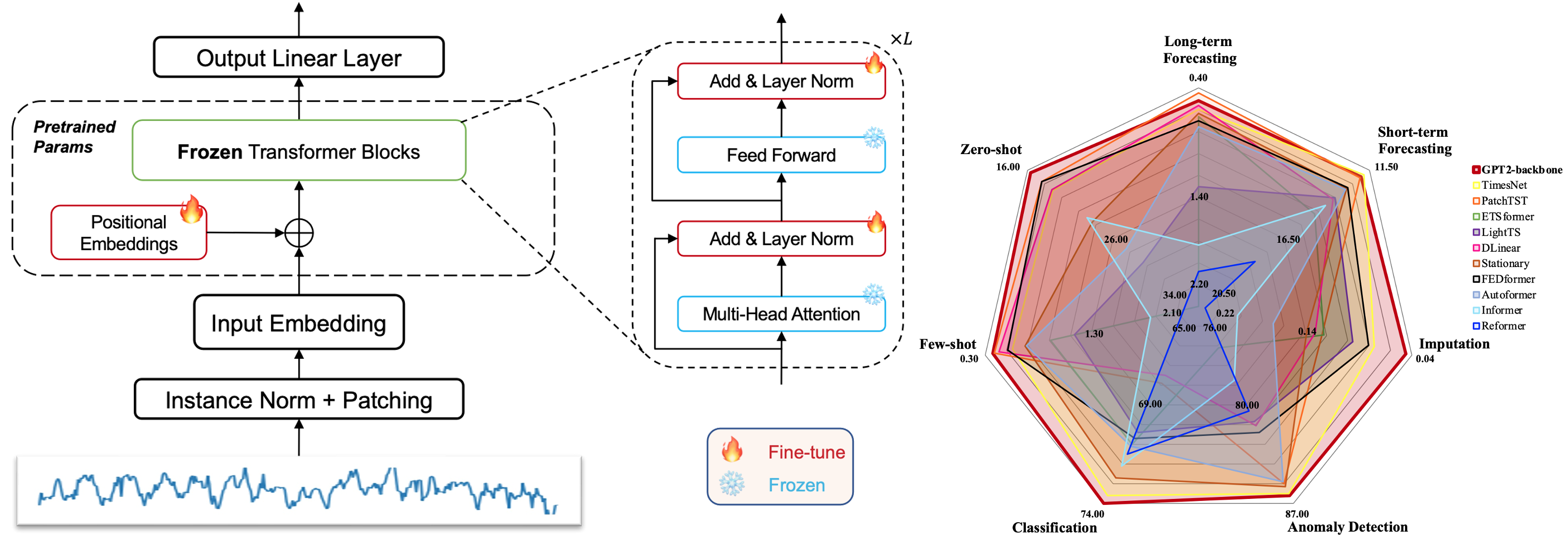
出典:[Zhou+, 2023]のFigure 1とFigure 2
このような研究は、膨大なデータから事前学習モデルが獲得した汎用的な知識を利用できることに加え、時系列タスクのための大規模データセットの構築や、それを用いた事前学習にかかるコスト・時間を大幅に削減できるため有望です。今後の研究動向にも注目したいと思います。
LLM × Data-Centric AI
2020年にOpenAIの研究者たちが発表した論文[Kaplan+, 2020]で示されたScaling Lawでは、データセットのサイズが増加するにつれてTransformerベースの言語モデルの性能が向上することが経験的に示されました。この発見以降、言語モデルの学習に使用されるデータセットのサイズは急激に増加し、この傾向は今後も続くことが予想されています。一方、[Villalobos+, 2022] では将来的なデータセットの枯渇に対して警鐘を鳴らしています。この研究では、現在のLLMの開発トレンドが続いたと想定した場合の学習データセットの需要の成長を予測した結果、下図のように2026年から2032年の間にモデルが利用可能な人間が作成した公開テキストデータの量とほぼ同じサイズのデータセットが学習に利用されることを示しました。つまり、人間が作成した公開テキストデータでは、現在のLLMのスケーリングを10年も維持できないと主張しています。
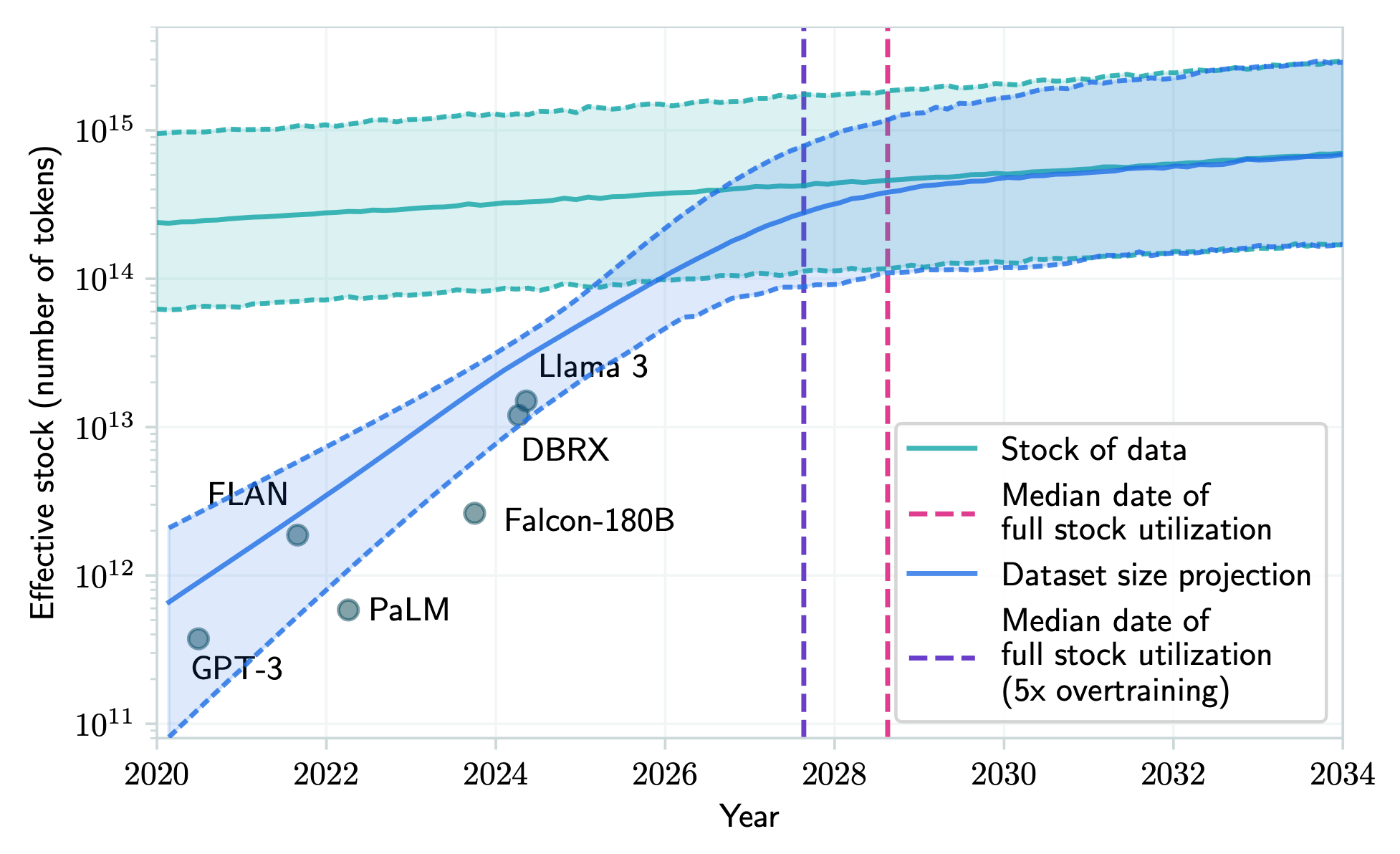
出典:[Villalobos+, 2022]のFigure 1
この課題を解決するためには、LLMの学習に用いるデータセットの量だけではなく質にフォーカスすることが重要です。データの質を向上させることは、Scaling Lawの形・傾きを劇的に変化させる可能性があり、より小さなモデルや少ないデータで高い性能を実現することが期待できます。しかし、効果的な学習データセットの根底にある重要なファクターは未だよくわかっていません。そのため、まずデータセットの良さを評価するためのData-centricなベンチマークの構築が必要です。Data-centricなベンチマークとは、データを固定してモデルや学習コードを改善する従来の機械学習のベンチマークとは逆で、モデルや学習コードを固定してデータセットを改善していくアプローチです。この代表的な研究として、マルチモーダルデータセット設計のためのベンチマークであるDataCompがあります。DataCompは、大規模な学習データセットを構築する際に発生する重要な課題として、与えられたデータソースをどのようにフィルタリングするか(Filtering track)、およびどのデータセットで学習するか(Bring your own data track)の二つに焦点を当てています。下図は、全体的なDataCompのワークフローを示しています。本論文では、二つの有力なフィルタリング手法を組み合わせることで作成した新たなマルチモーダルデータセットDataComp-1Bを用いて学習したモデルが、OpenAIのオリジナルのCLIPモデルを上回る性能を達成したことが報告されており、データセットのフィルタリングの重要性を強調しました。
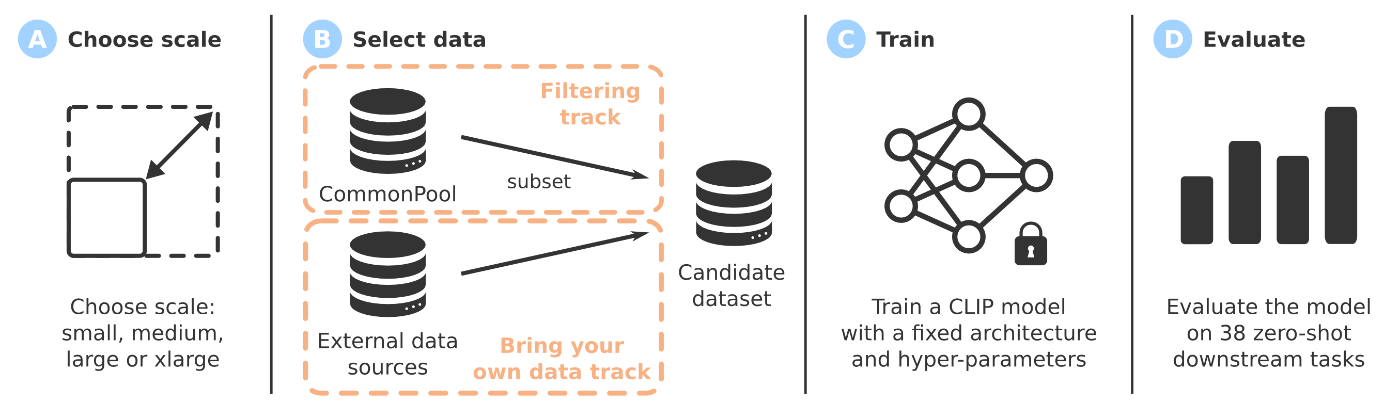
出典:[Gadre+, 2023]のFigure 1
また、LLMは推論時にデータを柔軟に利用し、出力の質を向上させることができるという他の機械学習モデルにはないユニークな能力を持っています。そのため、学習段階と同様に推論段階においてもLLMに与えられるデータが重要です。例えば、GPT-3の論文 [Brown+, 2020]では、推論時に解きたいタスクに関する説明に加えて少数の例を与えるFew-shot learningによりモデルの性能が向上することを示しました。この際に提示する例の選択や品質は、LLMの応答の品質に大きく影響を与えることが知られています。例えば、[Lu+, 2021]では、モデルに与える例の順序がモデルの性能に影響を与えることを示し、効果的な順序について議論しました。
以上のように、LLMでは、学習段階と推論段階のどちらにおいてもデータが重要な役割を果たすため、LLMの性能を最大限発揮させることを目指して、様々な観点からデータを生成、制御、最適化する研究が盛んに進められています。Data-centricな研究や開発は、まだデファクトスタンダードが確立されていないことや、個々のドメインや組織ごとに期待することが異なることなどから、研究・開発者が取り組むべき課題が多いはずです。私自身も今後はData-centricな視点を大事にして今後の研究・開発を進めていきたいと思います。
さいごに
本記事では、時系列データ分析とData-centric AIの二つの視点からLLMの研究動向について紹介しました。より詳細を知りたい方は、個人ブログで公開している時系列データ分析とData-centric AIのそれぞれの記事を読んでいただければ幸いです。どちらの研究領域も、ここ数年で急速に発展しており、現在もなお盛んに研究が進められています。さくらインターネット研究所では、今後もLLMに関する最新研究の調査や、それらの知識や技術を活かした研究に取り組んでいきたいと考えています。