NeurIPS 2025参加レポート:新設のPosition Paper TrackとAI4Mat Workshopでの発表
はじめに
さくらインターネット研究所の鶴田(@tsurubee3)です。このたび、大規模言語モデル(LLM)を用いた実験プロセスの構造化データ抽出に関する研究論文が、AIおよび機械学習分野の最難関国際会議であるNeural Information Processing Systems (NeurIPS) 2025のAI for Accelerated Materials Discovery (AI4Mat) Workshopに採択されました。
Workshopは会期後半の開催でしたが、初日のメインカンファレンスから現地参加してきました。本記事では、NeurIPS 2025の概要、新設されたPosition Paper Trackの概要、そして自身のポスター発表について報告します。
NeurIPS 2025の概要
NeurIPS 2025は、2025年12月2日から7日にかけて、アメリカ・カリフォルニア州サンディエゴで開催されました。

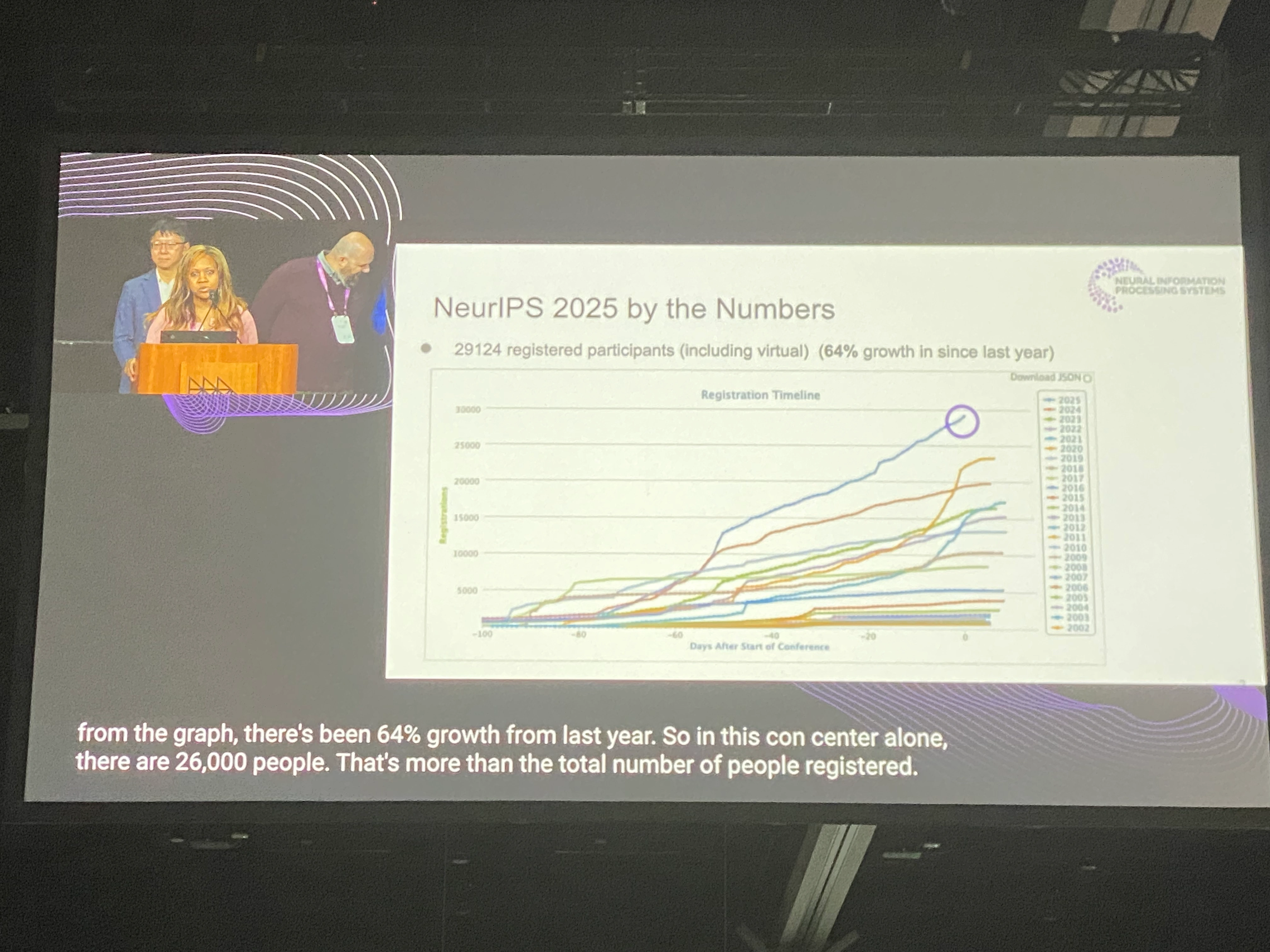
会場となったSan Diego Convention Centerには世界中から研究者が集まり、Opening Remarksで発表された数字によると、バーチャル参加者を含めた参加者総数は29,124名にのぼりました。また、Main Trackへの今年の論文投稿数は21,575件、採択率は24.52%でした。
Position Paper Trackの新設
NeurIPS 2025ならではの特徴の一つとして、Position Paper Trackが新設されたことが挙げられます。ICML 2024・2025に続く形での導入であり、NeurIPSとしては初めての試みとなりました。
このトラックの重要性を語る上で欠かせないのが、近年の論文投稿プラットフォームの大きな変化です。2025年10月、arXivのコンピュータサイエンス(CS)カテゴリにおいて、レビュー論文(サーベイ論文)およびPosition Paperの投稿を「ジャーナルやカンファレンスで採択・査読されたもの」に限定するという運用変更が発表されました。arXivという「誰でも自由に未査読のアイデアを公開できる場」で投稿要件が厳格化された今、NeurIPSという最高峰のカンファレンスで厳格な査読を勝ち抜き、「お墨付き」を得たPosition Paperを読めることの価値は、これまで以上に高まっていくと思います。
Position Paperとは
NeurIPS 2025 Call for Position Papersによると、Position Paperは以下のような役割を担うものとされています。
Position Paperとは、すでに達成された研究成果を報告する「Research Track」の論文とは対照的に、「今後何がなされるべきか」という視点や展望についての議論を展開するものです。また、個別の研究領域を超えた、機械学習分野全体に対するメタレベルの視点を持つことが求められます。
つまり、具体的なアルゴリズムの提案よりも、「私たちはどこに向かうべきか」というビジョンや、現在の研究の進め方に対する提言に重きを置いたトラックと言えます。
独自の査読基準
Position Paper Trackでは、査読の基準もResearch Track (Main Paper Track)とは大きく異なります。
- Research Track: 研究の独創性や、新規性のある結果を重視
- Position Paper Track: その主張が「機械学習コミュニティにおいて、より広く議論されるべき説得力のある主張を提示しているかどうか」が最大の判断基準
たとえ査読者がその主張に個人的に賛成できなくても、それがコミュニティにとって有益で建設的な議論を促すものであれば高く評価されます。公式に「議論を呼ぶような(Controversialな)トピックも歓迎する」と明言されている点も、このトラックのユニークな特徴です。
採択状況
初開催となったPosition Paper Trackを振り返る公式ブログが公開されています。ブログによると、初回の投稿数は約700件に達し、運営チームも予想を上回る反響があったとしています。取り下げやデスクリジェクトを除くと、496件が本審査の対象となりました。この中から40件の論文がカンファレンスでの発表に選ばれ、採択率は他のトラックと比較しても非常に低い約8%でした。この低い採択率の背景には、採択された論文に対して、より集中的な注目を集めるという事務局側の戦略的な判断があったようです。
現地での発表:オーラルとパネルディスカッション
NeurIPS 2025では、採択された40件のPosition Paperの中から3件のオーラル発表と2件のパネルディスカッション(それぞれ3件の論文で構成)が選ばれました。ここでは、どのようなPosition Paperが採択されているかを概観するために、簡単に内容を紹介します。
オーラル①「Position: If Innovation in AI systematically Violates Fundamental Rights, Is It Innovation at All?」
規制とイノベーションは対立するものではなく、むしろ適切な規制こそがイノベーションの基盤となると主張しています。EU AI Actをリスクベースかつ責任重視の規制モデルとして検討し、規制サンドボックスや中小企業支援などの適応的メカニズムが、技術的進歩を遅らせるのではなく責任ある形で加速させることを示しています。
自動運転や監視システムの開発において、公共の場でのデータ収集が歩行者の同意なしに行われている現状に警鐘を鳴らしています。AIコミュニティに対してデータ収集・匿名化の方法を再考するよう呼びかけています。
リアルタイムで生成される超パーソナライズされたAIコンテンツが、SNS中毒を超える「デジタル・ヘロイン」とも言える依存性の危険を指摘しています。特に若年層のメンタルヘルスへの悪影響を防ぐため、依存性薬物と同様の厳格な政府監視と、開発者向けの倫理ガイドラインの策定を強く訴えました。
パネルディスカッション①「Responsible AI Research & Unlearning: From Consent to Compliance to Critique」
責任あるAI/ML研究に向けて、データに対する同意の問題とモデルのアンラーニングの技術的・法的課題に焦点を当てた3つの論文が取り上げられました。
- 「Stop the Nonconsensual Use of Nude Images in Research」:裸体検出や裸体画像データセットに関する研究が、しばしば同意なく進められ、非同意のコンテンツの流通を正常化し、被害を永続させている問題を指摘しています。
- 「Position: Bridge the Gaps between Machine Unlearning and AI Regulation」:機械学習モデルのアンラーニング(データの影響の削除など)技術と、EU AI Actなどの既存の規制フレームワークを比較検討し、法的・技術的なギャップを明らかにしています。
- 「Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice」:生成AIシステムにおける技術的なアンラーニング手法と、法律・政策の関係者がこれらの手法に期待するものとの間のミスマッチを深く掘り下げています。
パネルディスカッション②「Strengthening the AI Research Ecosystem: Integrity, Critique, and Consensus」
機械学習研究エコシステムの構造的な脆弱性を指摘し、大胆な改革を提案する3つの論文が議論されました。
- 「Stop DDoS Attacking the Research Community with AI-Generated Survey Papers」:AI生成による大量生産されたサーベイ論文の急増を、研究記録を氾濫させ劣化させる「サーベイ論文DDoS攻撃」の一形態として問題提起しています。
- 「Position: Machine Learning Conferences Should Establish a ”Refutations and Critiques” Track」:主要なMLカンファレンスには、先行研究に対する厳密な批評や訂正のための信頼性・可視性の高い場が欠如していると主張し、専用の「反論・批評」トラックの創設を提案しています。
- 「NeurIPS should lead scientific consensus on AI policy」:NeurIPS(ひいてはMLコミュニティ全体)がAI政策に関する科学的コンセンサスの形成において積極的な役割を果たすべきであると主張し、エビデンスの統合と意思決定における重要なギャップを埋めることを求めています。
AI4Mat Workshopでのポスター発表
NeurIPSでは例年、メインカンファレンス終了後に各Workshopが並列で開催されます。NeurIPS 2025では合計56のWorkshopが2日間にわたって開催されました。私は2023年から3年連続でNeurIPSに参加していますが、2024年のAlphaFold関連のノーベル賞受賞などの影響もあってか、AI for Science系のWorkshopは参加人数も増え、非常に盛り上がっているように感じました。
私は「AI4Mat Workshop (AI for Accelerated Materials Design)」にてポスター発表を行ってきました。「AI4Mat Workshop」は、材料科学とAIの研究者が、AIによる材料発見の最前線を切り開く課題や成果を議論・共有する場として2022年に発足したワークショップです。今年は他のWorkshopと比べても大きな部屋が割り当てられており、参加者数も多く盛況でした。
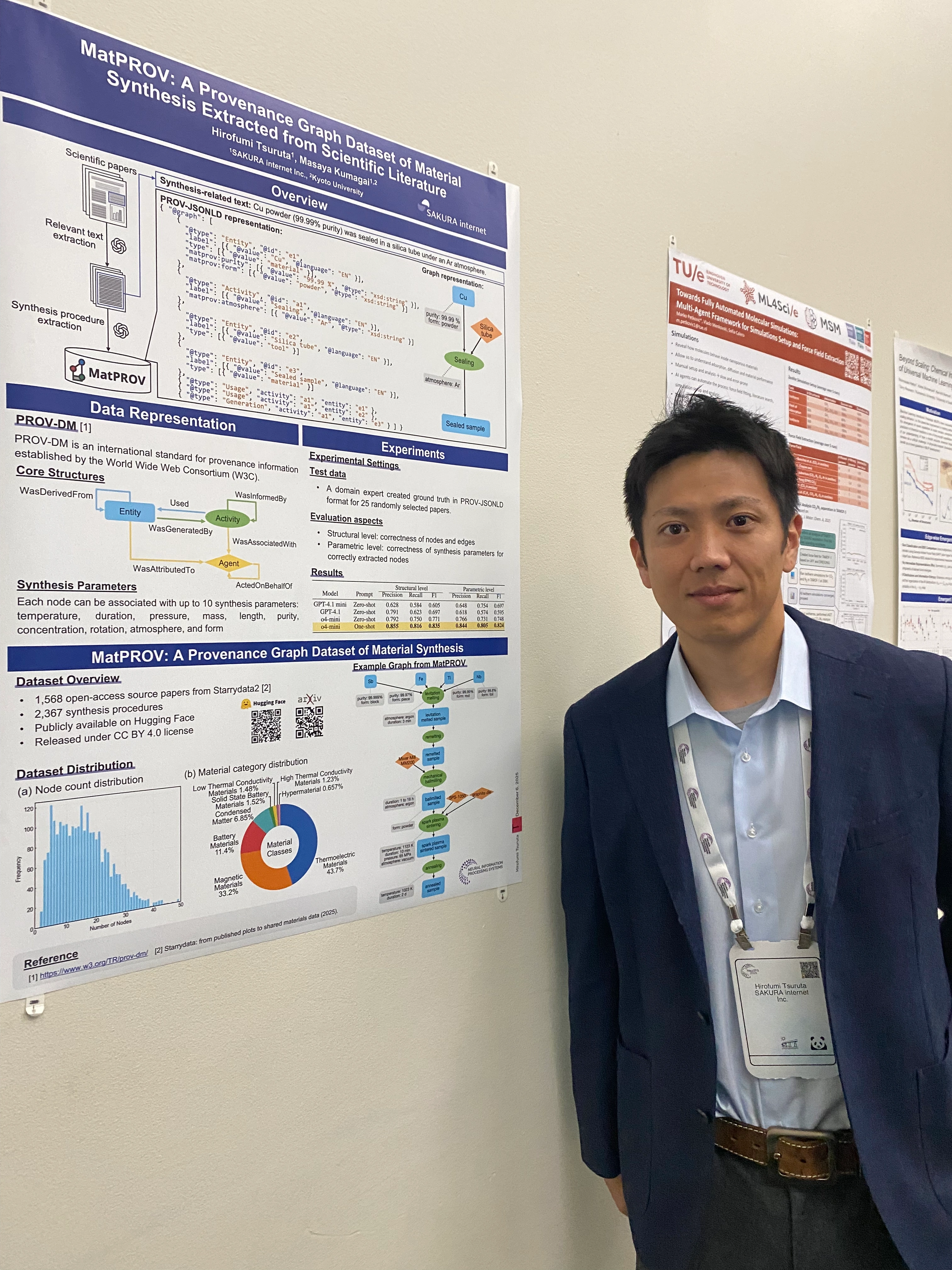
NeurIPSのメインカンファレンスでは、各ポスターに専用の展示ボードが用意されるのが通例ですが、ワークショップは少し勝手が異なります。写真のように、会場の壁面に自分の好きな場所を見つけてポスターを直接貼り付けるという、スタイルとなっています。AI4Mat Workshopではポスター数も多かったため、隣のポスターとの間隔が数センチしかないような密集地帯も多く、発表しづらさを感じる場面もありました。

そんな過密状態の中での発表でしたが、セッション中は聴衆が絶えることがなく、研究内容への関心の高さを実感しました。本研究の内容は、以前のブログ「LLMによる構造化データ抽出に関する論文が「NeurIPS 2025 AI4Mat Workshop」に採択」にて解説しています。
今回の発表で特に手応えを感じたのは、公開したデータセットに対する反応です。多くの参加者がその場でポスターに記載したQRコードを読み込んでダウンロードページにアクセスしていたのが印象的でした。このことは、我々の研究成果が理論的な貢献に留まらず、具体的な研究リソースとしても実用性・有用性を認められたことを示しており、大変嬉しく思いました。
おわりに
NeurIPS 2025への参加を通じて、機械学習コミュニティが技術的な成果だけでなく、研究の方向性や倫理的課題についても活発に議論する場へと進化していることを実感しました。新設されたPosition Paper Trackは、「私たちはどこに向かうべきか」という問いを正面から扱う貴重な試みであり、今後の発展が楽しみです。また、AI4Mat Workshopでのポスター発表では、公開したデータセットへの関心の高さから、研究成果が実際に活用される手応えを得ることができました。この経験を糧に、さくらインターネット研究所からより実用的で価値のある研究成果を生み出せるよう、引き続き研究開発に取り組んでいきたいと思います。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。