LLMによる構造化データ抽出に関する論文が「NeurIPS 2025 AI4Mat Workshop」に採択
さくらインターネット研究所の鶴田(@tsurubee3)です。このたび、大規模言語モデル(LLM)を用いた実験プロセスの構造化データ抽出に関する研究論文が、AIおよび機械学習分野の最難関国際会議「Neural Information Processing Systems (NeurIPS) 2025」のAI for Accelerated Materials Discovery (AI4Mat) Workshopに採択されました。採択された論文の情報は次の通りです。
- タイトル:MatPROV: A Provenance Graph Dataset of Material Synthesis Extracted from Scientific Literature
- 著者:Hirofumi Tsuruta, Masaya Kumagai
- URL:https://arxiv.org/abs/2509.01042
本論文の発表は2025年12月6日(土)にアメリカ・カリフォルニア州サンディエゴにて行います。本記事では、本論文の内容をご紹介します。
研究の概要
科学の知識の多くは、科学論文中の非構造化テキストとして記述されています。近年、こうしたテキストから科学的に有用な知識を構造化データとして抽出・表現することへの関心が高まっています。特に材料科学における合成手順は、材料特性を左右する重要な情報であり、その自動抽出と構造化は合成計画やプロセス最適化などへの応用が期待されています。
本論文の全体像を下図に示します。論文テキストから合成に関連する記述を抽出し、LLMを用いて材料・操作・実験器具・条件などの要素とその関係性を、PROV Data Model (PROV-DM) に準拠したJSON-LD形式として出力します。本研究で構築した「MatPROV」データセットは、1,568本の論文から抽出した2,367件の合成手順で構成されています。このデータセットの特徴は、合成手順を直感的に理解できる有向グラフとして表現できる点にあります。

PROV-DMとは
PROV-DMは、World Wide Web Consortium (W3C) が策定した来歴情報(provenance)を記述する国際標準モデルです。PROV-DMにおいて来歴情報は、以下のようにエンティティ・アクティビティ・エージェントの3種類のノードによって表現されます。つまり、来歴情報は、エージェントが責任を負うアクティビティによるエンティティの利用と生成を通じて表現されます。
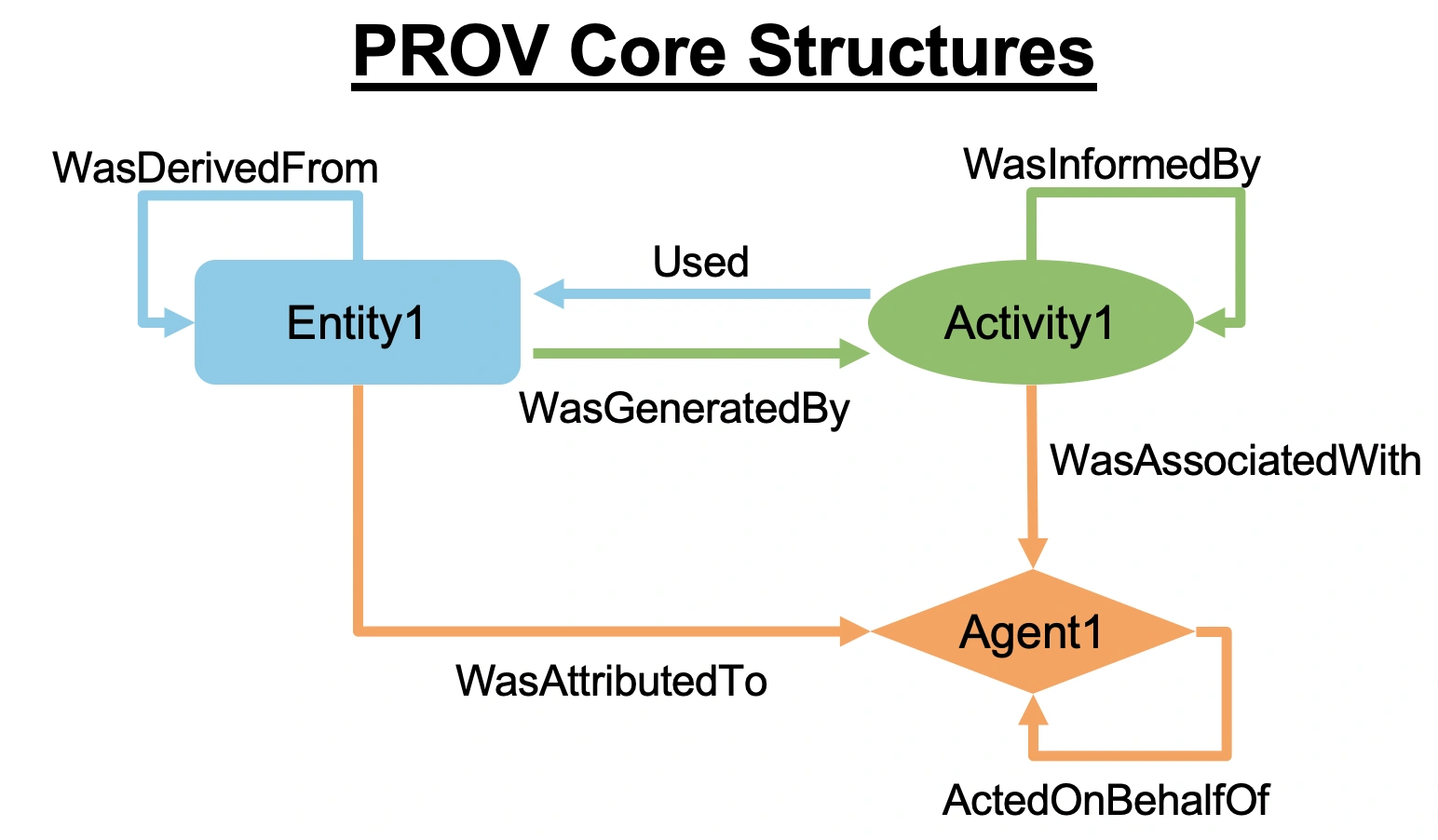
本研究では、このPROV-DMを材料合成手順の表現に応用しました。具体的には、
- エンティティ: (1) 前駆体・中間生成物・最終生成物などの材料、(2) 実験器具
- アクティビティ: 実験操作(例:加熱、混合)
にマッピングしています。科学論文における合成手順において、責任主体(エージェント)は、実験者またはその所属機関を暗黙に想定しているため、本研究ではエージェントは省略しました。
さらに、MatPROVでは合成に特化した10種類のパラメータ(温度、時間、圧力、質量、長さなど)を各ノードに付与できるよう拡張しました。これにより、PROV-DM標準に準拠しつつ、詳細な合成条件を記録可能にしています。この統一的なフレームワークによって、異なる材料分野の手順を比較したり、機械学習による解析に活用することが可能になります。
データセット構築方法
データセットは次の3ステップで構築しました。
- 論文収集:材料物性の実験値をキュレーションしたWebデータベースStarrydata2から、1,648本のオープンアクセス論文を収集
- 関連テキスト抽出:収集した論文から、LLMを用いて材料合成に関する記述のみを抽出
- 合成手順抽出:抽出したテキストをもとに、LLMで合成手順をPROV-JSONLD形式のグラフとして出力
データ抽出精度の評価
データセット構築方法の3番目のステップ(合成手順抽出)の精度を検証するため、30本の論文(計44件の合成手順)を対象に専門家が正解データ(Ground Truth)を作成し、3種類のOpenAIモデルの性能を比較しました。
評価は2つの粒度で行いました。
- 構造レベル:合成手順を構成するノード(材料・操作・器具など)とエッジ(それらの関係)の正確性を評価。
- パラメータレベル:各ノードに付随する属性(温度・時間・圧力・濃度などの条件値)が正しく抽出されているかを評価。
精度は、適合率(Precision)、再現率(Recall)、およびその調和平均である F1スコア を用いて測定しました。これにより、構造の正確さと条件情報の正確さの両面からモデルの性能を定量的に比較できます。
その結果、推論型モデルo4-miniが最も高い精度を示しました。この結果から段階的な合成手順をグラフとして正しく抽出するためには、高度な推論能力が必要であることが示唆されます。

さらに、ワンショット学習の効果も検証しました。具体的には、5つの論文から作成した合成手順の正解データを1例ずつ提示し、それぞれの抽出精度を比較しました。その結果、複雑なグラフ構造(20ノード)を含む例を与えた場合にF1スコアが最も向上しました(ゼロショットと比較して、構造レベルで+6.4%、パラメータレベルで+7.6%)。この結果は、モデルが複雑な手順のパターンを事前に参照できると、その後の抽出精度が改善することを示しています。つまり、難しい合成手順の例を一つ見せるだけで、複雑な手順理解が深まるという効果が確認できました。

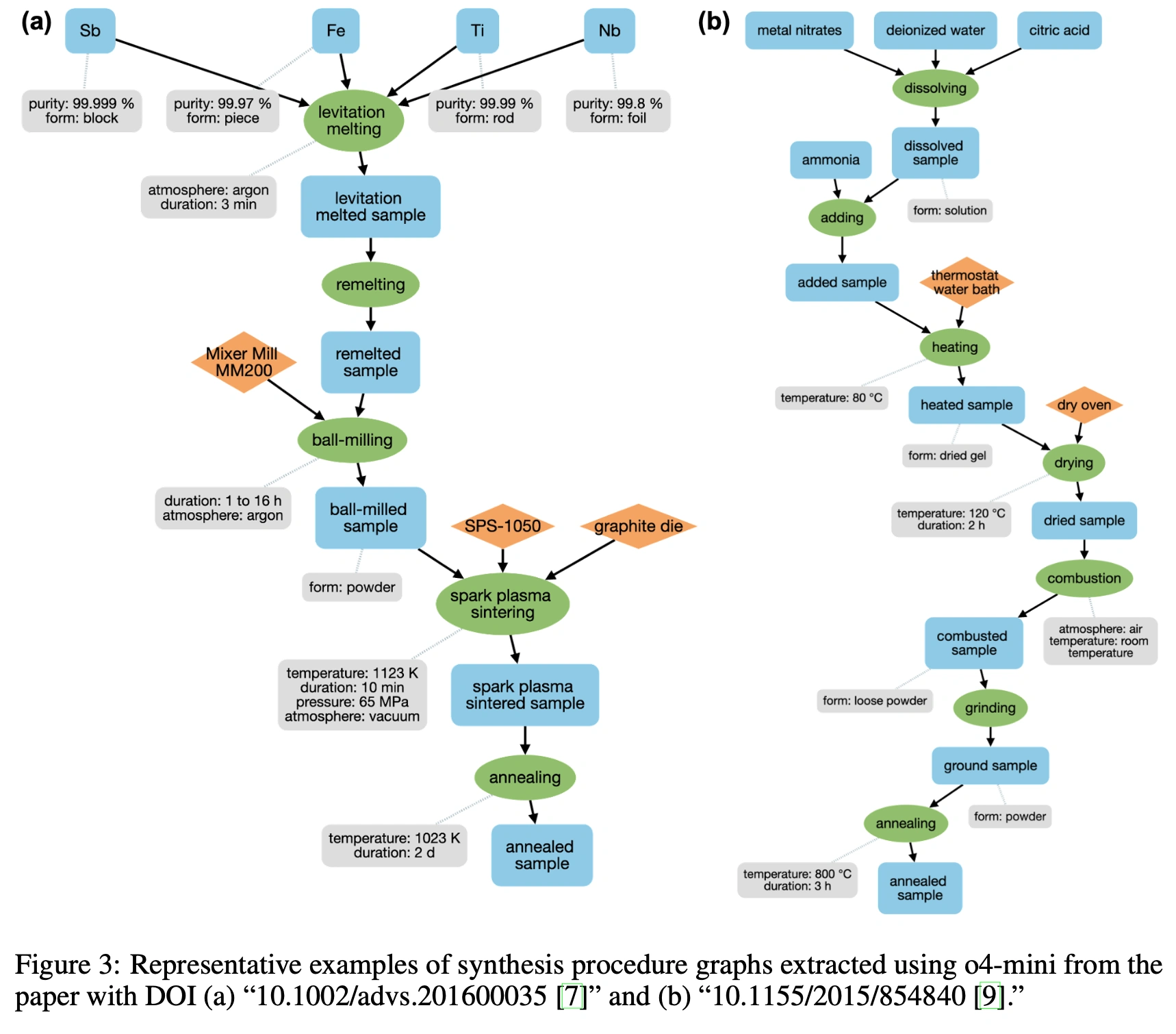
最後に、本研究のアプローチにより実際に抽出された合成手順グラフの例を以下に示します。これらは熱電材料(左)や磁性材料(右)の論文から得られた手順を可視化したもので、このような比較的複雑な合成手順がLLMにより抽出できていることがわかります。単なる文章の羅列では把握しづらい手順の流れが、グラフ化することで一目で理解できる形になっており、LLMによる抽出が実用的なレベルに達していることを直感的に示しています。
データセットの分析
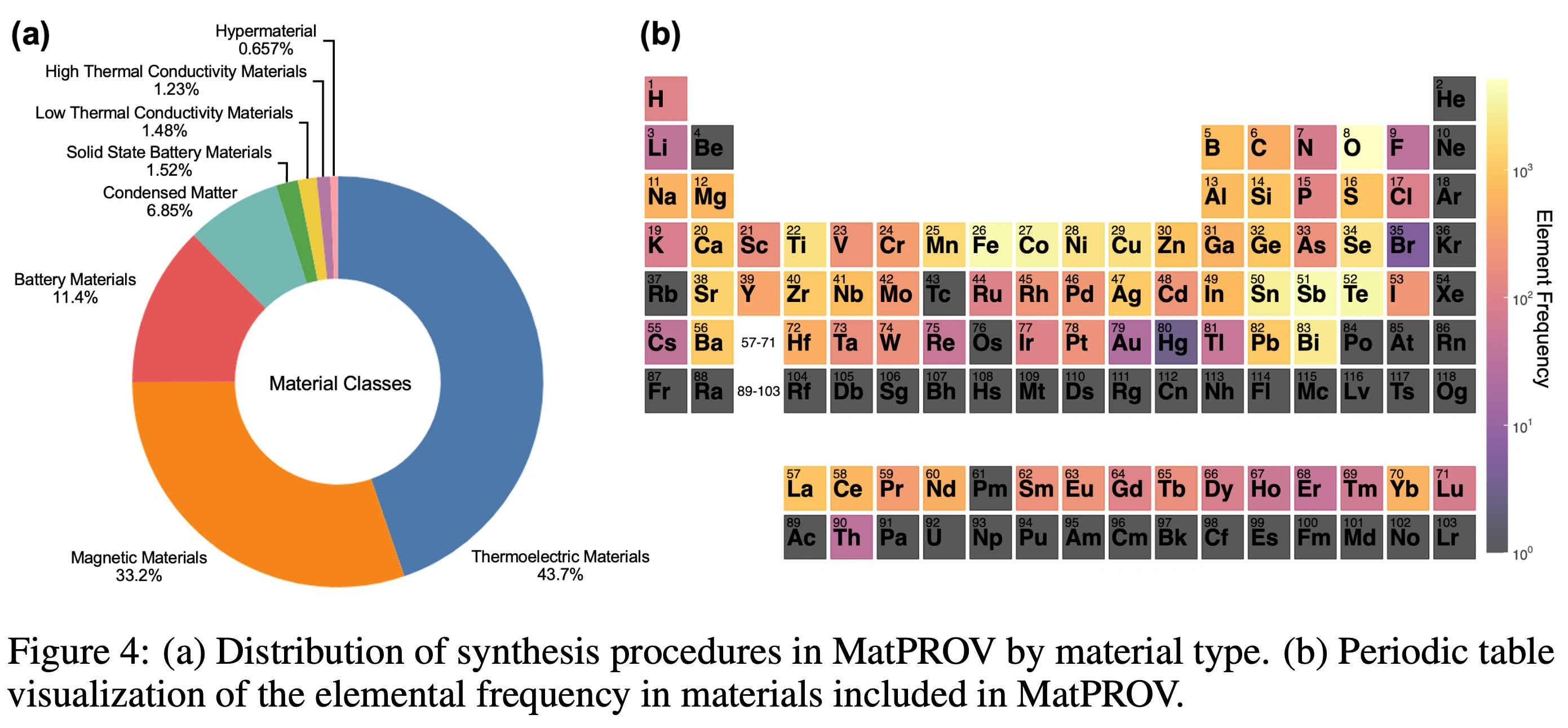
MatPROVには2,367件の合成手順が含まれており、そのうち98%以上が正しく有向非巡回グラフ(DAG)として表現されました。下図はMatPROVに含まれる合成手順の分布を示しています。Figure 4(a)は材料タイプごとの割合を示しており、熱電材料が約44%、磁性材料が約33%、電池材料が約11%を占め、この3分野だけで全体の8割以上を構成しています。Figure 4(b)は材料に含まれる元素の出現頻度を周期表上に可視化したもので、Bi、Sb、Te、Pb、Seなど熱電材料に典型的な元素や、Fe、Co、Ni、Mnといった磁性材料に多い元素が高頻度で現れています。これらの結果から、MatPROVが特定分野に偏りつつも、材料科学の主要領域を幅広くカバーしていることが確認できます。
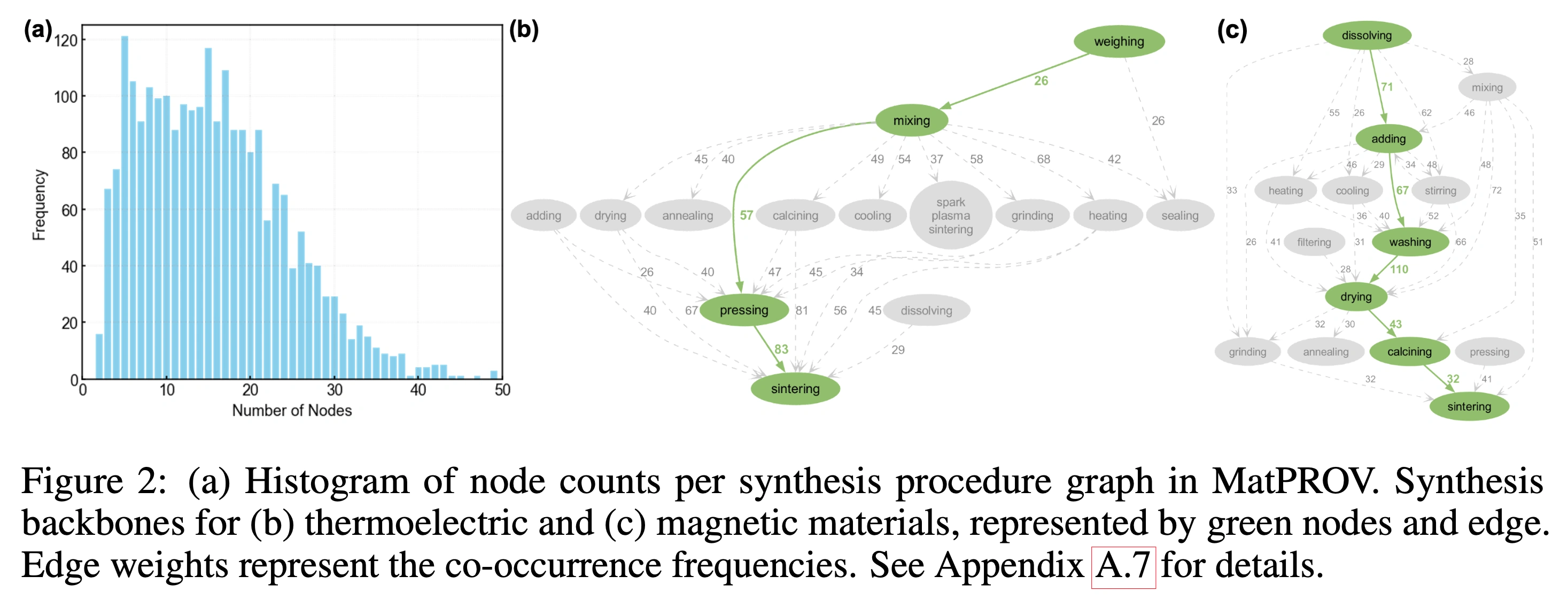
次に、MatPROVに収録されているグラフの特徴を分析します。Figure 2(a)はグラフごとのノード数を示したヒストグラムで、多くは5〜20ノード程度ですが、30ノードを超えるような複雑な合成手順も抽出されていることが確認できます。これは、単純なレシピから高度に分岐したプロセスまで幅広く表現できることを示しています。
Figure 2(b)と(c)は、それぞれ熱電材料と磁性材料における合成手順の骨格構造を示しています。分析の結果、熱電材料では粉末の混合(mixing)や焼結(sintering)といった固体プロセスが中心である一方、磁性材料では湿式化学的な溶解(dissolving)や乾燥(drying)が多いなど、分野ごとに異なる特徴が現れました。
このように、MatPROVは単なる手順の集合ではなく、材料ごとの合成パターンの違いを浮き彫りにできることが分かります。今後、こうした分析をさらに拡張することで、材料分野間の共通点や相違点を体系的に理解し、プロセス設計や新材料探索に役立てる可能性が期待されます。
今後の展望
本研究には、まだデータセットの規模が十分でないことや抽出精度のさらなる改善が必要であるといった課題があります。今後は対象となる論文の範囲を広げ、より多様な材料分野を網羅することで、データのスケールと汎用性を高めていく予定です。また、LLMのプロンプト設計やモデルのファインチューニングを工夫することで、複雑な手順の理解や条件抽出の精度向上を目指します。こうした取り組みによって、材料科学における知識の活用方法が大きく変わり、AIによる研究加速の一助となることを期待しています。
さいごに
本記事では、NeurIPS 2025 AI4Mat Workshop に採択された、LLMを用いた実験プロセスの構造化抽出に関する研究をご紹介しました。本研究は、論文に埋もれている膨大な実験知識を機械が理解できる形に整理し、材料科学の発展を加速する基盤づくりを目指すものです。AIと科学の融合に関心のある方にとって、新しい研究のヒントや実践的な活用のきっかけとなれば幸いです。より詳しい内容にご関心のある方は、ぜひarXivに公開されている論文をご一読ください。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。