NeurIPS 2025招待講演:「異質な知能」としてのAI — 認知能力を評価する6つの原則
はじめに
さくらインターネット研究所の鶴田(@tsurubee3)です。2025年12月にサンディエゴで開催されたNeurIPS 2025に参加してきました。本記事では、サンタフェ研究所のMelanie Mitchell氏による招待講演「On the Science of "Alien Intelligences": Evaluating Cognitive Capabilities in Babies, Animals, and AI」の内容を紹介します。
近年、大規模言語モデル(LLM)は多くのベンチマークで人間を超えるスコアを達成しています。しかし、その高い精度は本当に「知性」や「理解」を示しているのでしょうか。Mitchell氏は、AIの認知能力評価における根本的な問題を提起し、発達心理学や比較認知科学の知見を踏まえた、より厳密な評価のための6つの原則を示しました。非常に示唆に富んだ講演でしたので、本記事ではその要点を共有します。

エイリアン・インテリジェンスとは
講演タイトルにある「エイリアン・インテリジェンス(Alien Intelligence:異質な知能)」とは、人間とは異なる形で知性を持つ存在を指す概念です。本講演の冒頭では、Terry Sejnowski氏の論文「Large Language Models and the Reverse Turing Test (2022)」から以下の一節が引用され、LLMの知性の本質についての疑問が投げかけられました。
ほんの数年前には予想もされていなかったことが起こり始めている。あたかも、不気味なほど人間的な方法でコミュニケーションができる宇宙人(エイリアン)が突然現れたかのようだ。ただ一つ明らかなのは、LLMは人間ではないということだ。しかし世界中のテキストデータベースから情報を抽出する能力においては超人的である。その行動の一端は知的に見えるが、もしそれが人間の知性ではないなら、その知性の本質とは何なのか?
ベンチマークの問題点
Mitchell氏はまず、今日の生成AIシステムが多くのベンチマークで人間のパフォーマンスを超えている一方で、実世界のタスクにおいては依然として人間とは異なる形で苦戦していることを指摘しました。この背景には、現在のAI評価手法には以下のような深刻な問題があります。
- データ汚染:学習データにテストデータの内容が含まれている。
- 近似的な検索:真の理解ではなく、検索やパターンマッチングに近い形で回答している。
- 疑似相関の利用:表面的な相関をショートカットとして利用して回答している。
- 一貫性・頑健性・汎化性の欠如:これらを検証するテストが不足している。
- 構成概念妥当性の欠如:測定しようとしている概念や特性を正しく測定できていない。
- 擬人化(anthropomorphism)の問題:人間向けテストの前提条件がAIシステムには当てはまらない。
発達心理学・比較認知科学からの知見
講演の核心は、発達心理学や比較認知科学からの知見の応用です。Mitchell氏はMichael Frank氏の論文「Baby steps in evaluating the capacities of large language models (2023)」ら以下の一節を引用しました。
エイリアン・インテリジェンスとの初めての接触を想像してみてください。科学者はこう問うかもしれません。エイリアンは人間と同じ概念を持っているのか?他者の心を理解できるのか?因果関係を推論できるのか?こうしたシナリオはSF作品でよく見られる。そしてここ数年、大規模言語モデル(LLM)との対話においても同様だ。しかし発達心理学者は長年、別のエイリアン・インテリジェンス、つまり人間の子どもについて同じ疑問を投げかけてきた。この研究の手法は、LLMの能力を探る上で研究者に役に立つだろう。
発達心理学者や比較認知科学者は、長年にわたり人間の乳幼児という、ある意味での「エイリアン・インテリジェンス」を研究対象としてきました。Mitchell氏は、これらの分野で培われた知見がAIの認知能力評価にも応用できると主張しています。
認知能力をより厳密に評価するための6つの原則
講演では、AIの認知能力をより厳密に評価するための「6つの原則」が提示されました。
1. 擬人化への認知バイアスを自覚する
講演中では例として、赤ちゃんが笑ったとき、人間は喜んでいると解釈するが、猿は恐怖やストレスを感じたときに笑ったような表情(Fear grimaceと呼ばれる)を示すことが挙げられました。それでは、AIが組み込まれたロボットが笑ったときはどう解釈すべきでしょうか。この例は、AIが人間と同じように感じたり考えたりしていると安易に思い込まないよう注意を促しています。

2. 仮説を疑う
観察された行動を生み出しうる代替戦略(暗記やショートカット)を考慮し、それらに対する統制を設計すべきです。これについては、乳児の道徳的な推論に関する論文「Social evaluation by preverbal infants (2007)」から非常にユニークな事例が紹介されました。この研究では、生後6〜10ヶ月の乳児に以下に示す2種類のアニメーション動画を見せます。左側がHelperシナリオで、赤い丸のキャラクターが坂を登ろうとするのを黄色い三角のキャラクターが後ろから押して助け、無事に坂を登りきります。一方、右側がHindererシナリオで、赤い丸のキャラクターが坂を登ろうとするのを青い四角のキャラクターが上から押し戻して邪魔をし、坂を登れません。この2種類の動画を見せた後、乳児にどちらのキャラクターがより好きかを選んでもらいます。

出典:「Social evaluation by preverbal infants」のFigure 1
その結果、乳児は有意にHinderer(青い四角)よりもHelper(黄色い三角)を選びました。この論文では、乳児はキャラクターの社会的行動に基づいて他者を評価しており、道徳の概念を持っていると主張しています。しかし、後続研究の論文「Social Evaluation or Simple Association? Simple Associations May Explain Moral Reasoning in Infants (2012)」では、この乳児の選択は道徳的な概念ではなく、別の要因による単純な連想に起因することが示されました。実は元の動画では、Helperシナリオの場合のみ、丘の頂上まで登りきった際に赤いキャラクターが小さく小刻みにジャンプを繰り返す演出が含まれていました。そこで、Hindererシナリオでも丘を登れなかった際にキャラクターが小刻みにジャンプするよう変更したところ、Hindererを選ぶ乳児が有意に増えたのです。このように、観測される結果が本来意図していない要因によって引き起こされている可能性を常に疑う必要があります。
3. 失敗のタイプを分析する
多くの場合、失敗は成功よりも多くの洞察を与えてくれるため、ネガティブな結果を受け入れることが重要です。この点に関連して、ICML 2024で発表された論文「Position: Embracing Negative Results in Machine Learning (2024)」を紹介しています。この論文では、新しい機械学習手法を提案する論文が、選択された問題に対する予測性能のみで評価されがちな現状に警鐘を鳴らしています。著者らは、予測性能だけでは論文の価値を測る良い指標にはならないと主張しています。むしろ、予測性能のみを重視することは、機械学習研究コミュニティ全体の非効率性を助長し、研究者に誤ったインセンティブを与える問題を引き起こすと指摘しています。そこで著者らは「ネガティブな結果」の発表を呼びかけており、これによりこれらの問題の一部が緩和され、機械学習研究コミュニティの科学的成果が向上すると論じています。
4. 頑健性と汎化性をテストするためのバリエーションを設計する
この原則については、文字列の類推問題(letter-string analogy problems)が例に用いられました。文字列の類推問題とは、例えば「a b c d → a b c e」と与えられたときに「i j k l → ?」の答えを推論する(この場合、最後の文字を一つ進めて「i j k m」と答える)というような問題です。
2023年に発表された論文「Emergent analogical reasoning in large language models (2023)」では、文字列の類推問題においてGPT-3が人間を凌駕するスコアを達成したと報告されました。しかし、このようなLLMの文字列推論は本当に頑健なのでしょうか。この疑問を検証するため、Mitchell氏は自身の研究論文「Evaluating the Robustness of Analogical Reasoning in Large Language Models (2024)」を紹介しました。
本論文の実験では、元の類推問題の変種に対する頑健性を人間とGPTモデルで比較しています。具体的には、「a b c d」のような通常のアルファベット順の中でn個の文字の位置をランダムに入れ替えて再配置したアルファベットを用いた場合と、文字の代わりに非文字記号(non-letter symbols)を特定の順序で並べたものを用いた場合について、人間とLLMの類推精度を比較しました。その結果を以下の図に示します。
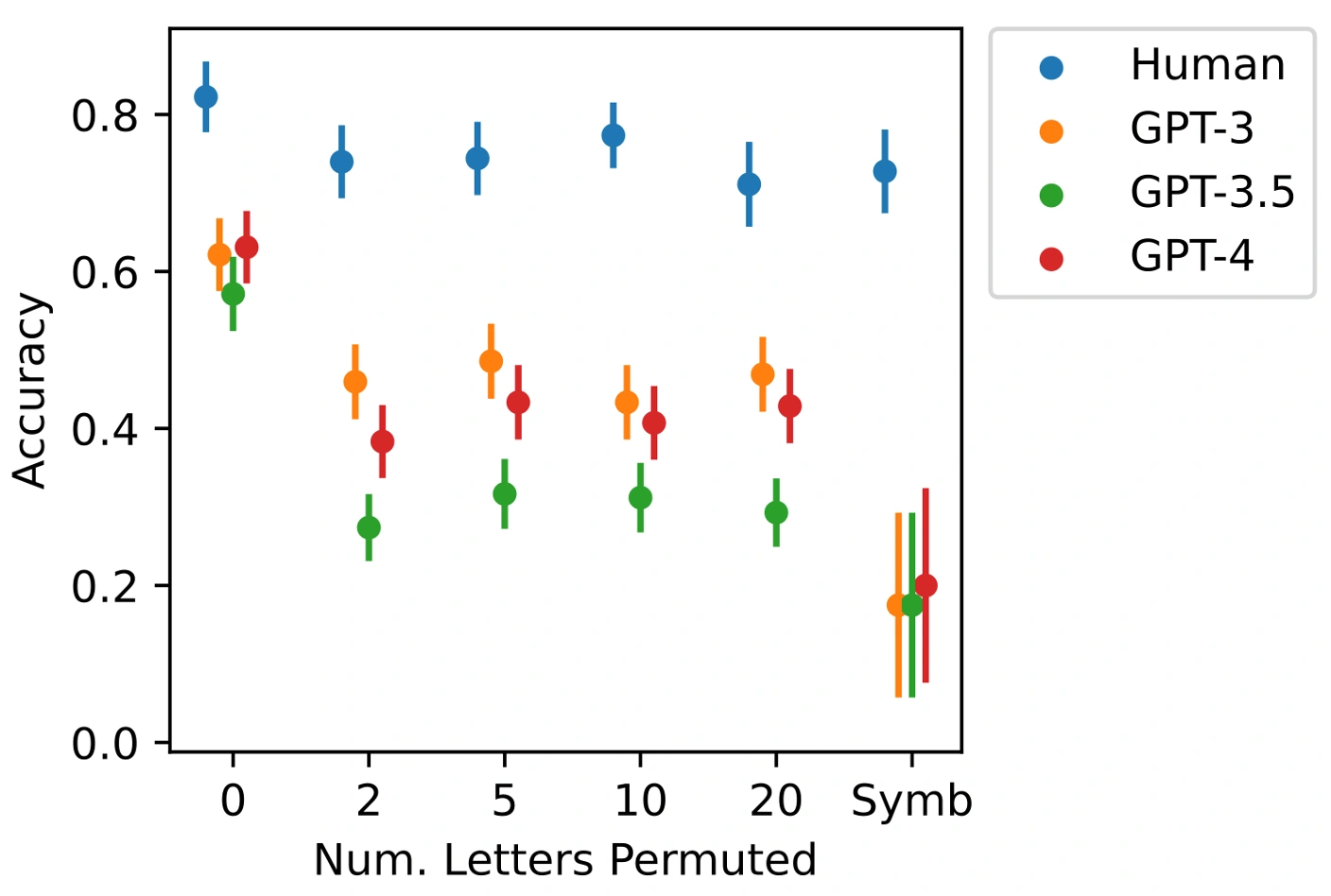
これらの変種問題は同じ抽象的推論能力をテストするものであり、真に類推能力を持っているならば、性能が著しく低下すべきではありません。しかし結果を見ると、人間は2種類の変種問題のいずれでも高い性能を維持している一方、GPTモデルの性能は急激に低下し、特に記号を用いた場合には著しく低下することが判明しました。このことは、LLMが人間の類推能力のような頑健性を欠いていることを示しており、AIシステムの認知能力を評価する際には精度だけでなく頑健性も慎重に検証すべきであることを示唆しています。
5. CompetenceとPerformanceを区別する
CompetenceとPerformanceは心理学や言語学でよく用いられる概念で、Competenceは「潜在的な知識・能力」を、Performanceは「その知識・能力を実際の状況で使った結果」を指します。システムがある能力(Competence)を持っていても、それを実際の状況で実行(Performance)できるとは限らず、逆もまた然りです。
この原則については、LLMの抽象化と推論能力を評価するためのAbstraction and Reasoning Corpus(ARC)が例に用いられました。ARCは、オブジェクト性、単純な幾何学と位相、基本的な数といった「コア知識」に基づいて手動で作成された1,000のタスクが含まれています。例えば、以下のようなタスクです。
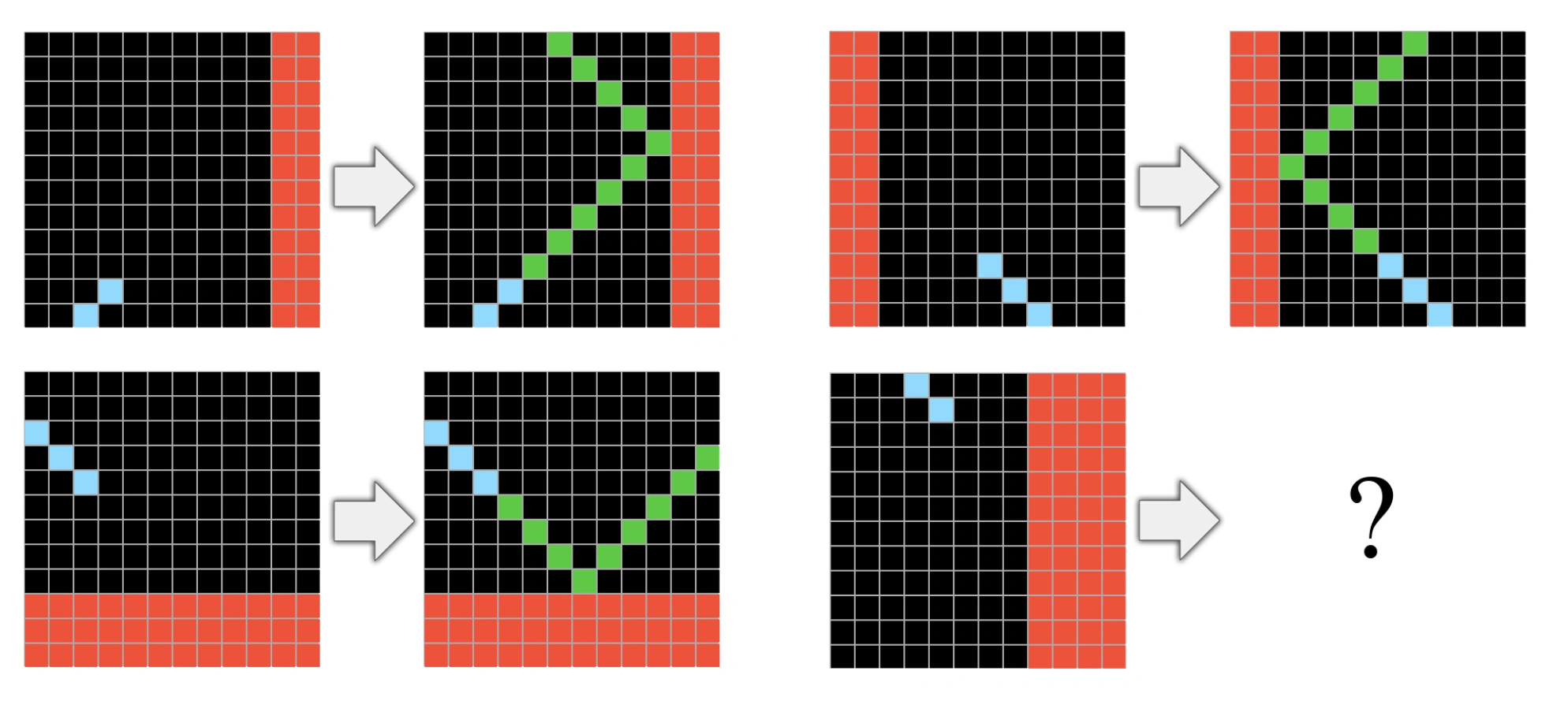
出典:「On the Measure of Intelligence (2019)」のFigure 8
このタスクでは、水色のピクセルの延長線が赤い障害物に接触すると「跳ね返る」というルールを外挿して解くものになっています。これらのタスクに対する人間の精度は64%程度であり、LLMはこれを超えられずにいました。しかし2024年、OpenAIのo3モデルがブレイクスルーを起こし、驚異の88%という精度を叩き出しました。
ここでMitchell氏はある疑問を投げかけました。これらのモデルは、意図された「コア知識」の抽象化をどの程度把握しているのか?それとも、これらの課題を解決するために「異質な」推論方法を用いているのか?
この疑問を検証した論文「Investigating Abstraction Capabilities of the o3 Model Using Textual and Visual Modalities (2025)」が、NeurIPS 2025のMultimodal Algorithmic Reasoning Workshopで発表されています。この論文はMitchell氏自身も共著者として参加しており、ARCを単純化したConceptARCベンチマークを用いてo3モデルの抽象化能力を評価しています。
実験では、o3に出力グリッドだけでなく、変換ルールを自然言語で説明させました。そして、生成されたルールを「correct-intended(タスク作成者が意図した抽象化を捉えている)」「correct-unintended(正しく機能するが、意図した抽象化を捉えていない)」「incorrect(誤り)」の3つに分類しました。以下の図はその結果を示しています。
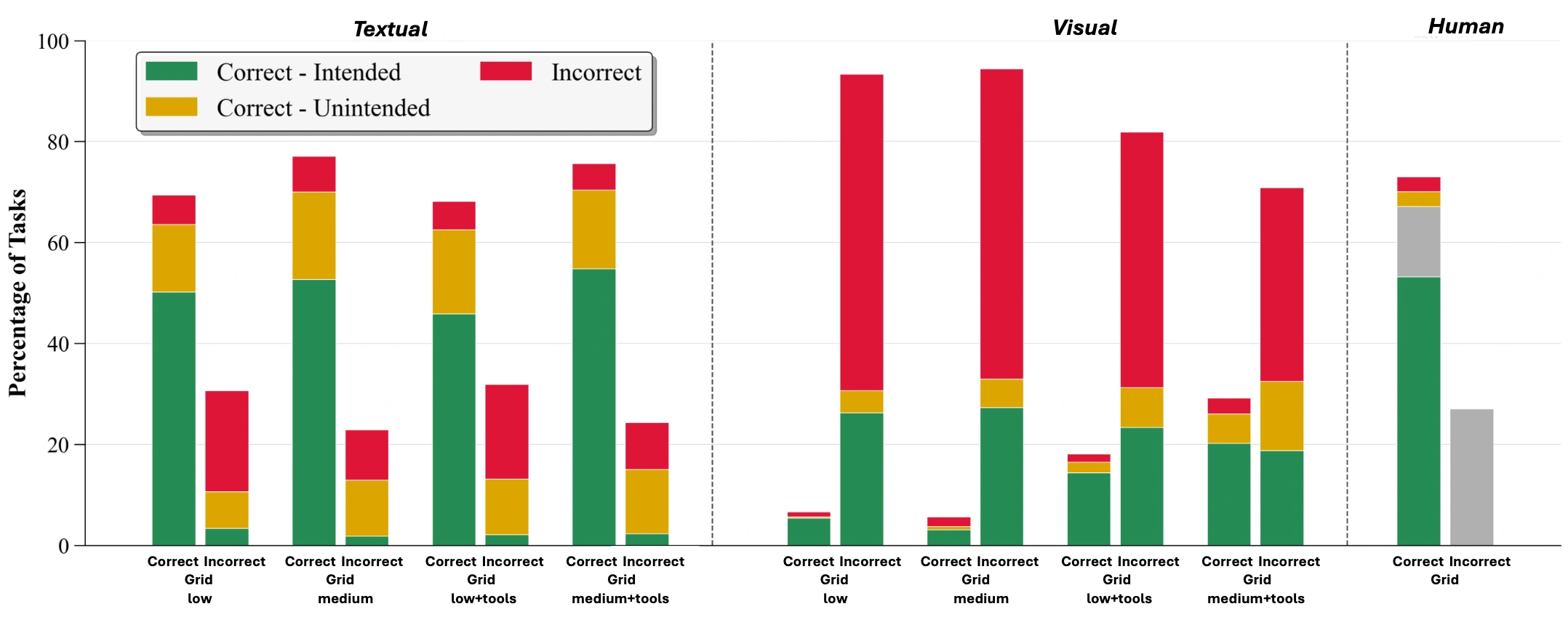
出典:「Investigating Abstraction Capabilities of the o3 Model Using Textual and Visual Modalities (2025)」のFigure 2
この実験では、入力モダリティ(テキスト形式か画像形式か)とReasoning effort(lowかmediumか)を変えて評価が行われました。テキスト入力・medium設定において、o3は出力グリッドの精度では人間に匹敵する性能を示しました。しかし、正解した出力のうち約28%は、correct-unintendedまたはincorrectなルールに基づいていることが判明しました。つまり、意図された抽象概念ではなく、表面的なパターンに基づいた推論で正解を導き出していたのです。一方、人間が生成したルールの約90%はcorrect-intendedでした。
テキスト形式では色が数値(例:黒=0、青=1、赤=2)でエンコードされているため、o3モデルの変換ルールはオブジェクトの形状ではなく、数値比較をショートカットとして利用するケースが見られました。correct-unintendedの具体例として、以下の図のTask 2を見てみましょう。
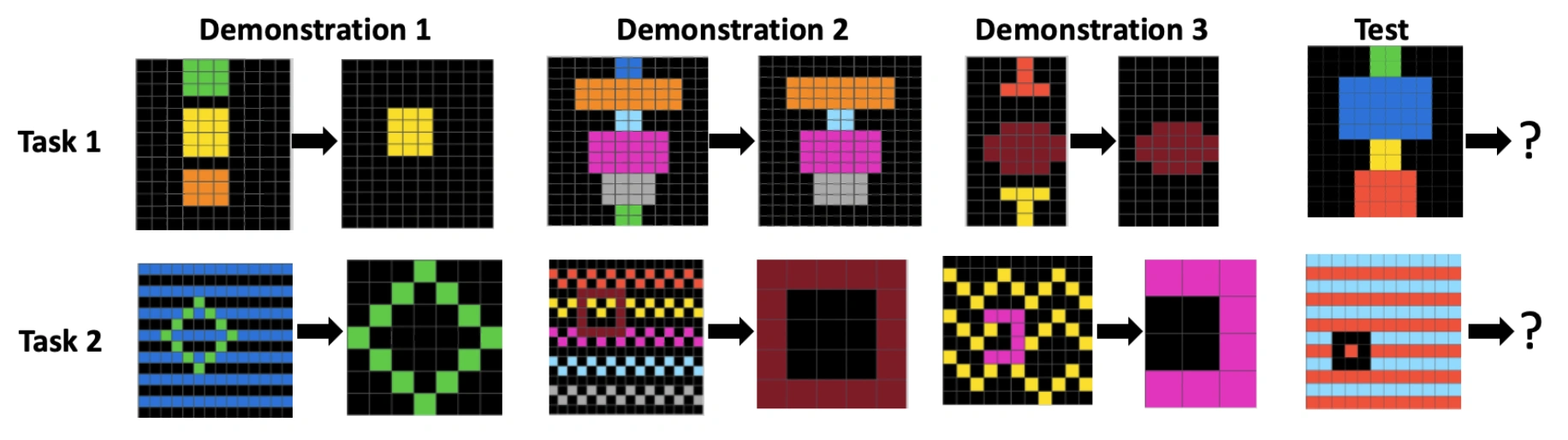
出典:「Investigating Abstraction Capabilities of the o3 Model Using Textual and Visual Modalities (2025)」のFigure 1
Task 2において、意図された変換ルールは次の通りです。「入力グリッドには、特定のパターンの中に場違いな図形が含まれている。出力グリッドはこの図形であり、寸法と色をコピーするが、入力グリッドに含まれる元のパターンはコピーしない。」これに対し、o3が生成した変換ルールは次の通りでした。「入力グリッド内で最も高い非ゼロの色値を持つセルをすべて含む最小の長方形を切り取る。この長方形の内側ではその色を保持し、他のすべてのセルを0(黒)に変換する。その長方形を出力する。」
o3のルールは、与えられたデモンストレーションに対しては正しく機能しますが、「場違いな図形を抽出する」という意図された抽象化を捉えておらず、代わりに「最も高い色値」という数値的なショートカットに依存しています。このため、本実験ではcorrect-unintendedと分類されました。
これらの結果は、AIシステムの認知能力を評価する際には、単純な精度だけでなく、頑健性やシステムが汎化可能なメカニズムを使用しているかどうかを評価することの重要性を浮き彫りにしています。
6. 他者の成果を再現し発展させる
先行研究を再現して異なる結果を得たり、少しだけ実験条件を変えて同じような結果を得たりした成果を学会に投稿すると、査読者から「新規性がない」と指摘されるかもしれません。しかし、優れた科学の特徴は、先行研究の再現とその「漸進的」な発展にあります。Mitchell氏は、このような研究に対してコミュニティがより価値を認めるようになることを望んでいると述べています。
実際に、本講演で紹介された研究事例も、先行研究の結果を疑い、異なる実験条件で検証したものばかりです。乳児の道徳的推論に関する研究では、元の実験の動画に含まれていた小刻みなジャンプという交絡要因を特定しました。文字列の類推問題では、アルファベットの順序を入れ替えたり記号に置き換えたりすることで、LLMの頑健性の欠如を明らかにしました。そしてARCベンチマークにおけるo3モデルの評価では、出力の正解・不正解だけでなく生成されたルールの質を分析することで、高い精度の裏に隠れたショートカット的推論を浮き彫りにしました。これらはいずれも、先行研究の追試や条件の変更を通じて、新たな洞察を得た好例といえます。
精度だけでは測れない知性
重要なメッセージとして、Mitchell氏はベンチマークでの高い精度が、必ずしもモデルがタスク作成者の意図した抽象概念を認識し推論していることを意味しないと強調しました。精度だけでは、表面的な特徴の利用やショートカット、人間らしくない推論を覆い隠してしまう可能性があります。人間とAIの「理解」の整合性についての洞察は、これらのシステムが人間世界でどのように能力を汎化させるかを予測するために不可欠です。
AIに求められる性質の二面性
また、Mitchell氏はAIシステムに人間と同じような推論が求められるかどうかは文脈によって異なることも指摘しました。AIシステムに求められる思考の在り方には二面性があります。
- 人間とは異なる思考が求められるケース:AlphaFoldがタンパク質・DNA・RNAの立体構造を予測し、データから新しいパターンを見出すような場面。
- 人間と同じ世界理解が求められるケース:自動運転車が、看板に描かれた一時停止標識の画像を本物の標識と誤認して急ブレーキをかけてしまうような、人間世界での安全性が問われる場面。
前者のように、AIシステムに人間とは異なる思考を期待する場合もありますが、後者のように人間社会で共生するシステムには、人間と同じように世界を理解することが求められます。人間とAIの「理解」がどれだけ一致しているかを知ることは、AIシステムが人間世界でどのように振る舞うかを予測するために不可欠です。
より厳密な評価手法の必要性
結論として、Mitchell氏は動物、子ども、そして機械といった「エイリアン・インテリジェンス」の本質を見極めるには、相当な厳密さと創造性が必要であると述べました。私たちはAI評価においてもっとそのような厳密さと創造性を必要としており、現在必要なのはより難易度の高いベンチマークを作ることではなく、本講演で紹介した原則に基づいた、より厳密な評価手法を確立することなのだと締めくくりました。
まとめ
本講演を通じてMitchell氏は、AIがベンチマークで示す「高い精度」が、必ずしも人間のような「真の理解」を意味しないことを浮き彫りにしました。この課題に対処するため、発達心理学や比較認知科学の知見を応用した6つの原則が提示されました。これらの原則は、AIが「正解を出せるか」ではなく「どのように正解に至ったか」を問う姿勢の重要性を示しています。AIが科学の進歩に寄与する「異質な思考」を持つ一方で、人間社会で安全に機能するためには、私たちの世界理解と整合する頑健な汎化能力が欠かせません。精度という指標の先にある「知性の本質」を多角的に検証し続ける姿勢こそが、これからのAI研究においてますます重要になっていくのではないかと思いました。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。