MLSys 2026でAI/HPCクラスタ「さくらONE」の設計・性能評価・運用データ分析を発表
さくらインターネット研究所の鶴田(@tsurubee3)です。2026年5月、米国ワシントン州ベルビューにて、機械学習とシステムの交差領域における国際会議「Machine Learning and Systems(MLSys)2026」が開催されました。同会議のIndustry Trackに、当研究所が開発・運用する、AIモデル開発向けのHPC(High Performance Computing)クラスタ「さくらONE」に関する論文が採択され、共著者3名で現地に赴いて発表しました。本記事では、MLSys 2026のIndustry Trackの概要、採択論文の概要、現地でのオーラル発表・ポスター発表の様子について報告します。
MLSys 2026 Industry Trackについて
MLSysは、機械学習とシステムという2つの研究コミュニティが知見を共有し、新たな接点を生み出すことを目的に設立された国際会議です。2018年に「SysML」として第1回が開催されて以来、現在の名称に改称後も毎年開催されており、機械学習の効率化・大規模化を支えるシステム技術から実応用に向けた取り組みまで幅広いテーマが扱われています。
Opening Remarksで発表された数字によると、近年はMLSysへの投稿数が大きく伸びています。MLSys 2025の271件から、MLSys 2026では504件と前年比86%増加しており、機械学習システム分野への関心の高まりがうかがえます。
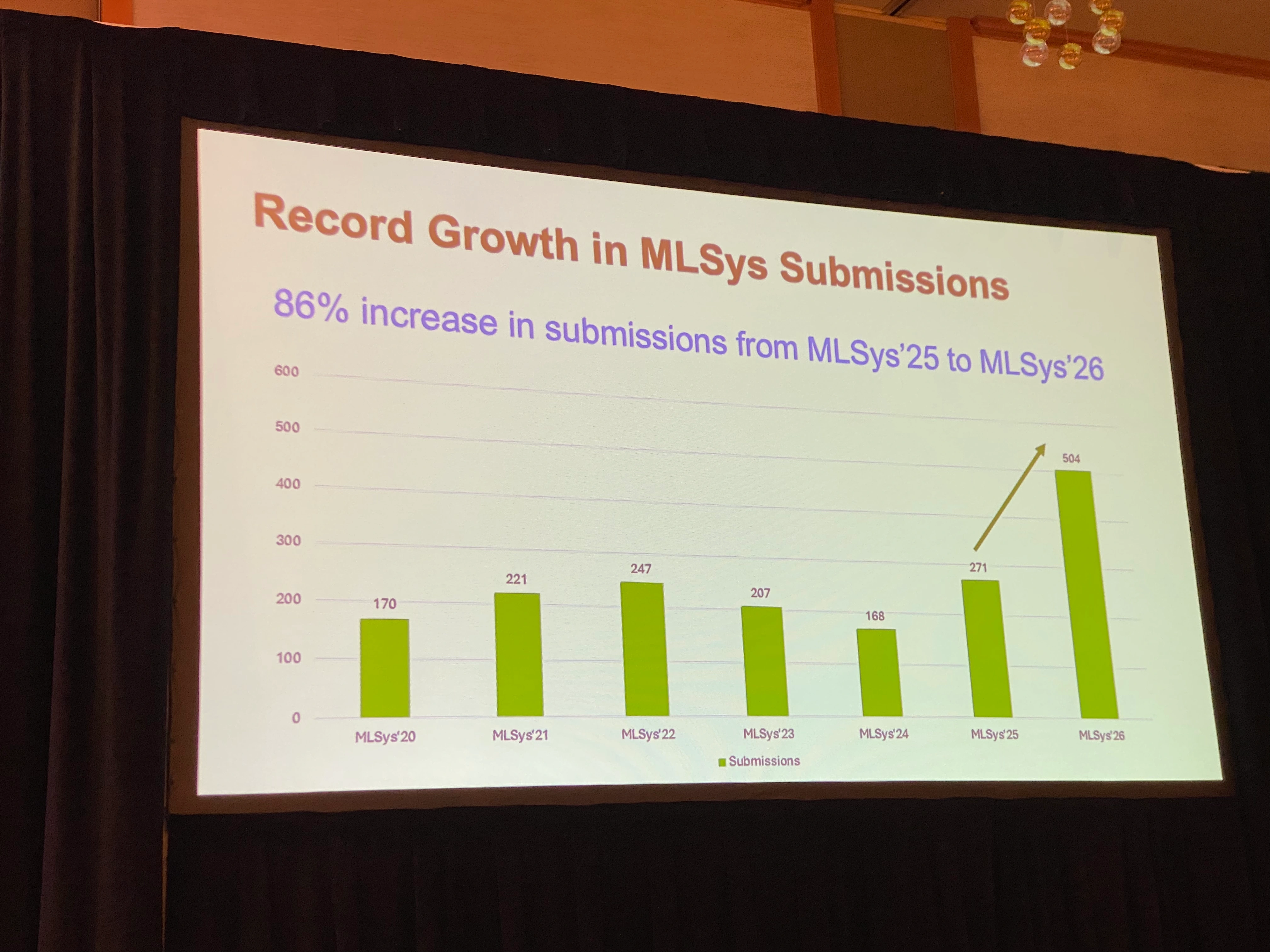
MLSys 2026では、従来のResearch Trackに加えてIndustry Trackが新設され、注目を集めました。Industry Trackには初年度ながら87本の投稿が集まりました。

Research Trackと比較したIndustry Trackの主な特徴は2点あります。1点目は、評価のフォーカスが「本番運用システムの設計・評価から得られた知見・教訓」に置かれていることです。研究の新規性そのものよりも、実世界での影響、技術的品質、システム構築から得られた経験が重視されます。2点目は、Research Trackのように完全な匿名化は求められないことです。投稿時には、著者名は匿名化しますが、製品名等の識別情報を本文に含めることが認められています。
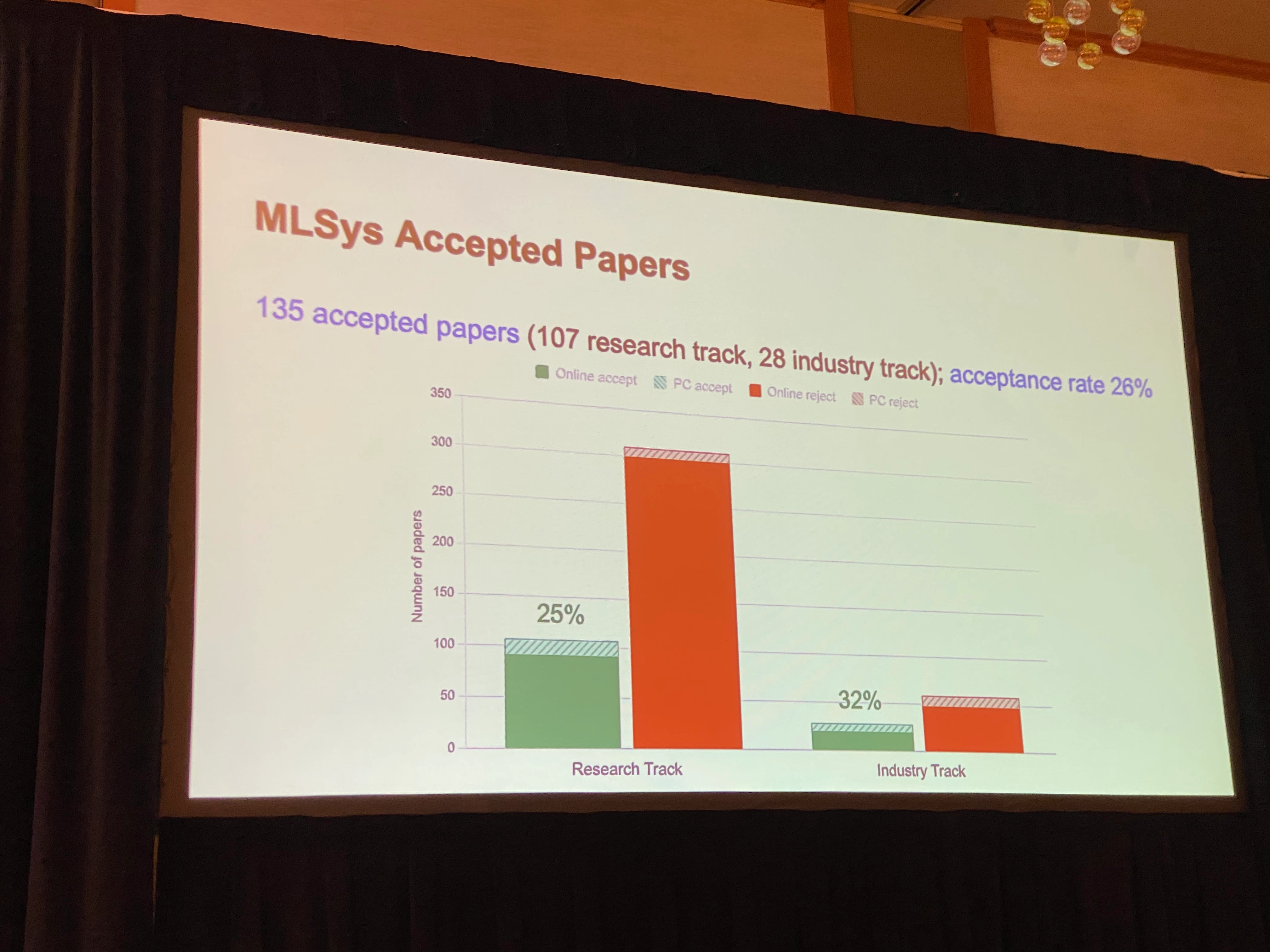
MLSys 2026全体では504本の投稿のうち135本の論文が採択され、内訳はResearch Track 107本、Industry Track 28本となっています。全体の採択率は26%、Research Track単体では25%、Industry Track単体では32%でした。
採択論文の概要
- タイトル: SAKURAONE: An Open Ethernet-Based AI HPC System and Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
- 著者: 小西史一、坪内佑樹、鶴田博文(さくらインターネット株式会社)
- 論文: https://arxiv.org/abs/2604.13600
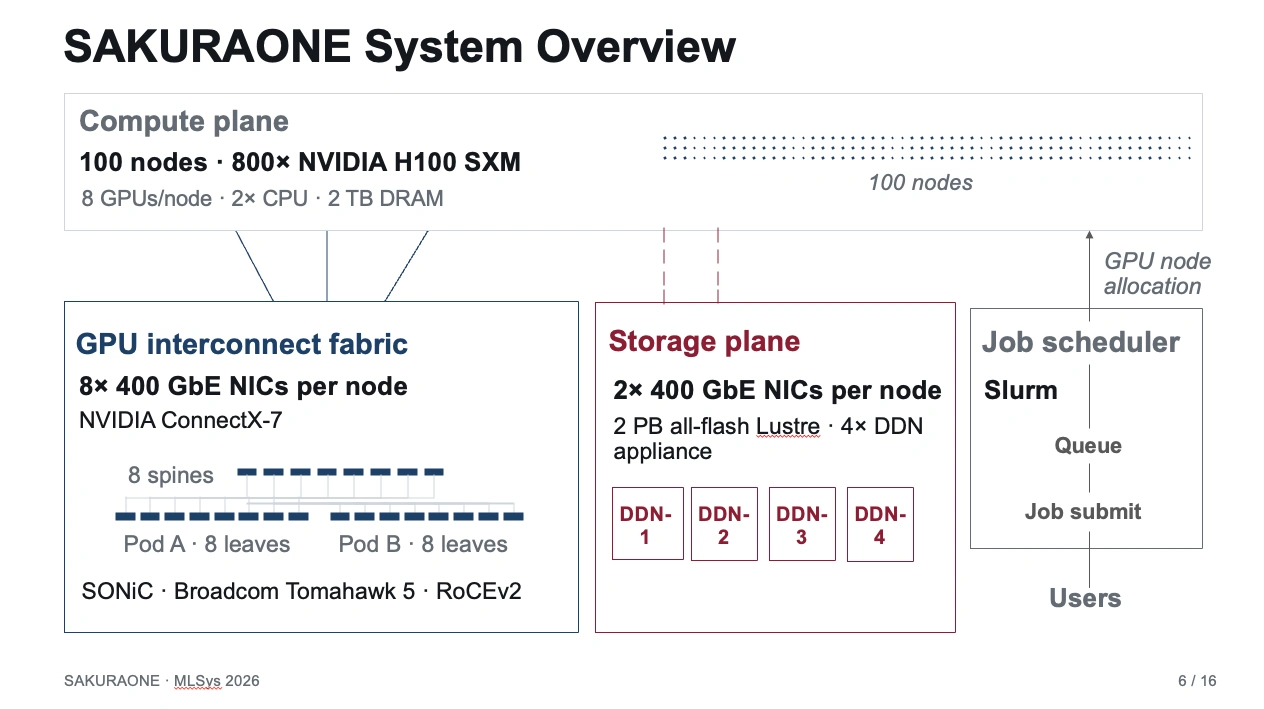
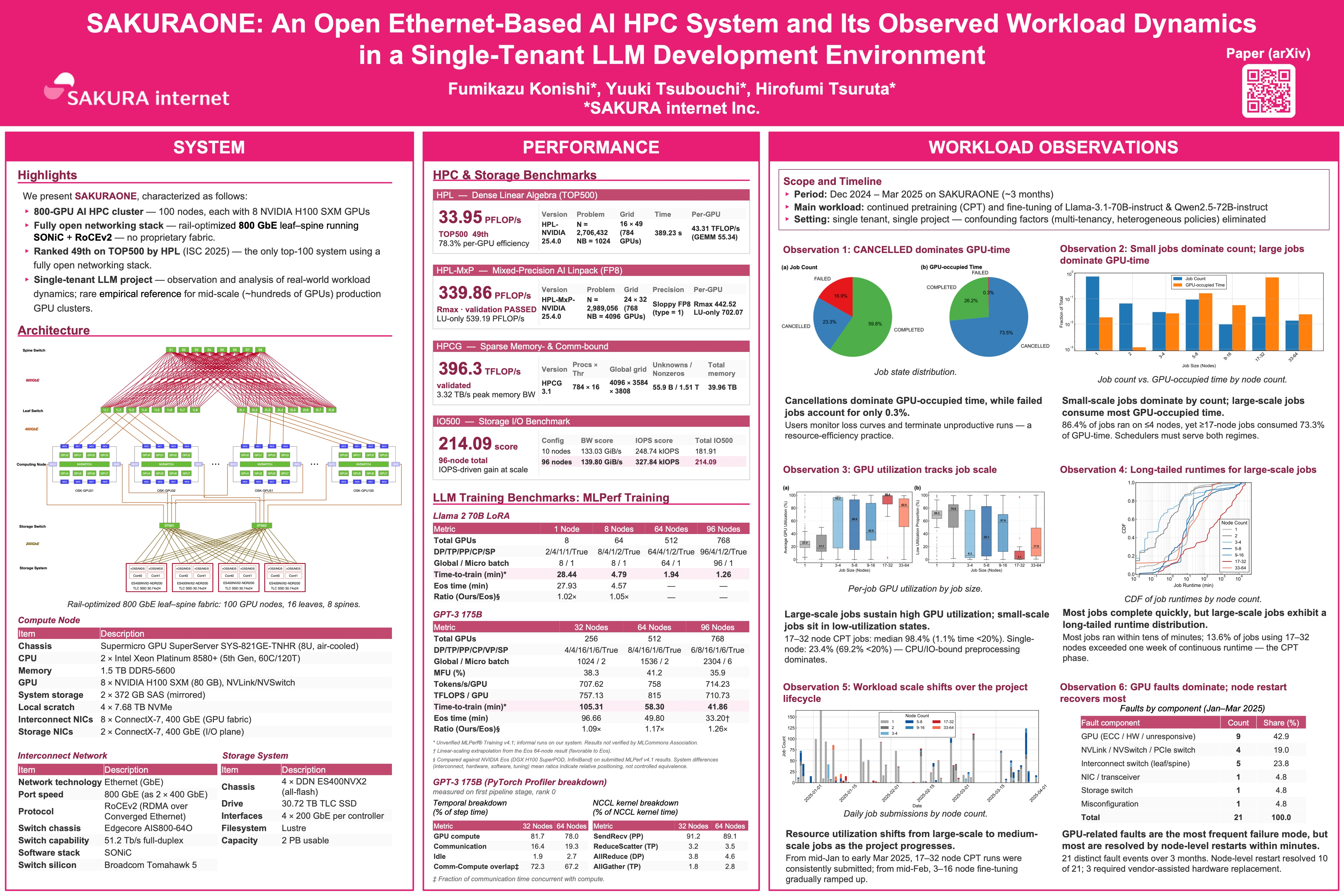
採択された論文は、「さくらONE」の設計と、TOP-500およびMLPerfに基づく性能評価、その上での大規模言語モデル(LLM)開発における実運用知見を報告したものです。さくらONEは、NVIDIA H100 GPUを800基(100ノード×8基)搭載したAI/HPCクラスタです。高帯域・低レイテンシが求められるAI向けAI/HPCクラスタでは、従来、特定ベンダーに依存した専用の相互接続ネットワーク(InfiniBandなど)が主流でした。これに対しさくらONEは、800ギガビットイーサネット(800 GbE)とネットワークOSのSONiC(Software for Open Networking in the Cloud)を組み合わせたオープンEthernetネットワークを基盤として採用している点が特徴です。
本論文では、以下の2点を中心に報告しています。
- ベンダーに依存しないオープンEthernetネットワークを基盤とするAI向けHPCシステムのアーキテクチャ設計・実装と性能評価
- 単一プロジェクト・単一テナント環境におけるLLM開発の実運用データに基づくワークロード特性の観測と分析
これらの取り組みは、オープンでコスト効率の高いAI/HPCクラスタの実現可能性を実証するとともに、実運用に基づくワークロード分析を通じて、次世代AIインフラの設計指針として産業界・学術界の双方に有用な知見を提供するものです。具体的な性能評価の結果やワークロード分析の知見については、後述のオーラル発表・ポスター発表のセクションで紹介します。
オーラル発表
オーラル発表は坪内(@yuukit)が担当しました。発表スライドは以下で公開しています。
発表の前半では、さくらONEのシステム設計を中心に説明しました。LLM開発においてピークFLOPSだけでなく、長期間にわたって継続的に利用できる計算資源、GPU間通信のための予測可能なネットワーク経路、そしてベンダーに依存しすぎないオープンな運用性を我々は重視しています。そこで、さくらONEでは100ノード・800基のNVIDIA H100 GPU、SONiC/RoCEv2 EthernetによるGPU間相互接続、GPU通信とストレージI/Oの分離、GPU-NIC affinityとrail-optimized topologyを組み合わせた設計を採用していることを説明しました。
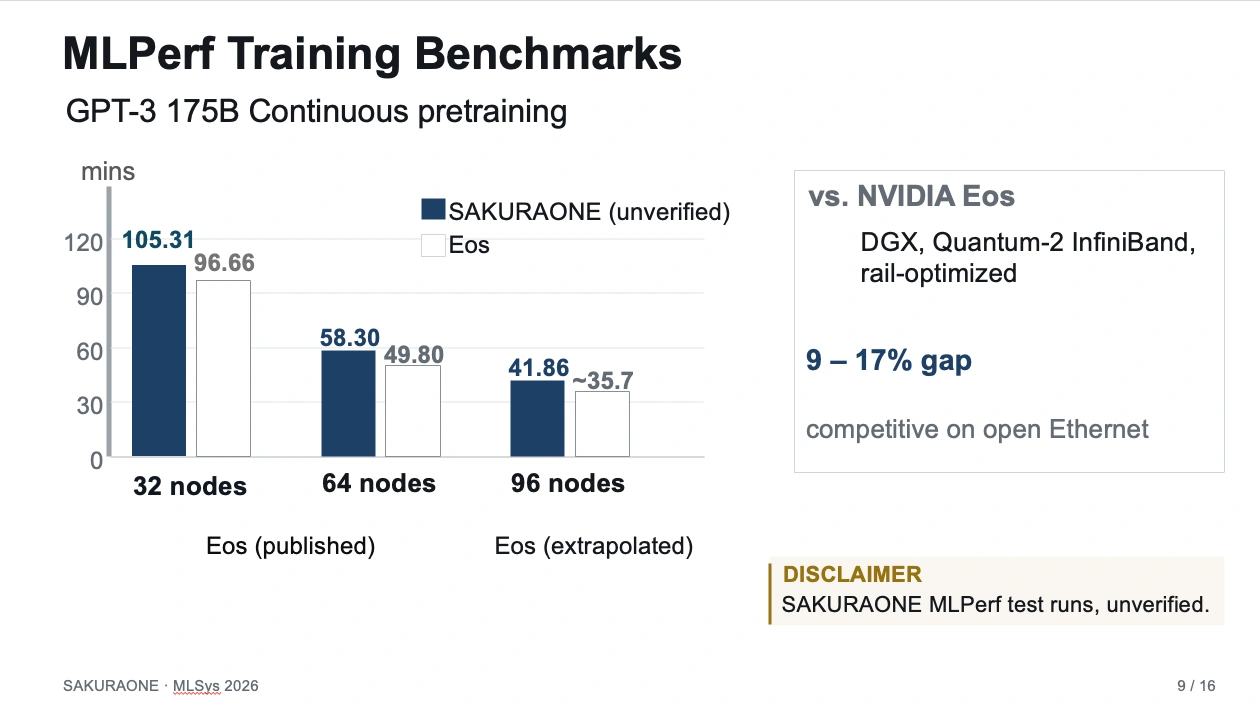
続いて、HPL、HPL-MxP、HPCG、IO500、MLPerf-style benchmarkの結果を示し、オープンEthernetを基盤とする構成でも、HPC・AI学習・ストレージを横断して競争力のある性能を示せることを説明しました。さくらONEがスーパーコンピュータの国際ランキングTOP-500 HPLベンチマークにて、49位を獲得したことは、当社のニュースリリースでも公開しています。
GPT-3 175Bを対象としたMLPerf-style benchmarkでは、32、64、96ノードでの実行結果を示し、公開されているNVIDIA Eosの参照値と比較して、同規模のノード数でおおむね9〜17%程度の差に収まることを紹介しました。
さらに、MLPerf GPT-3 175Bベンチマークテスト実行時のPytorch Profilerによるプロファイリング結果についても説明しました。この実行では、pipeline parallelismを16、virtual pipeline parallelismを6に設定しており、多数のpipeline microbatchが発生します。PyTorch profilerで確認したところ、NCCL時間の大部分はpipeline stage間のSendRecv操作で占められており、32ノードおよび64ノードの実行ではSendRecvがNCCL時間の約90%を占めていました。また、32ノードから64ノードへ拡大すると、通信時間の比率は16.4%から19.3%へ増加し、通信と計算のoverlapは72.3%から67.2%へ低下しました。64ノード実行は2つのpodにまたがる配置となるため、cross-pod placementも性能差に影響した可能性があります。

発表の後半では、単一LLM開発プロジェクトの運用トレースから得られた知見を紹介しました。特に強調したのは、ジョブ件数とGPU占有時間がまったく異なる傾向を示す点です。1ノードジョブはジョブ件数の76.9%を占める一方で、GPU占有時間では1.8%にとどまります。逆に、17ノード以上の大規模ジョブはジョブ件数では3.3%にすぎませんが、GPU占有時間では73.3%を占めていました。
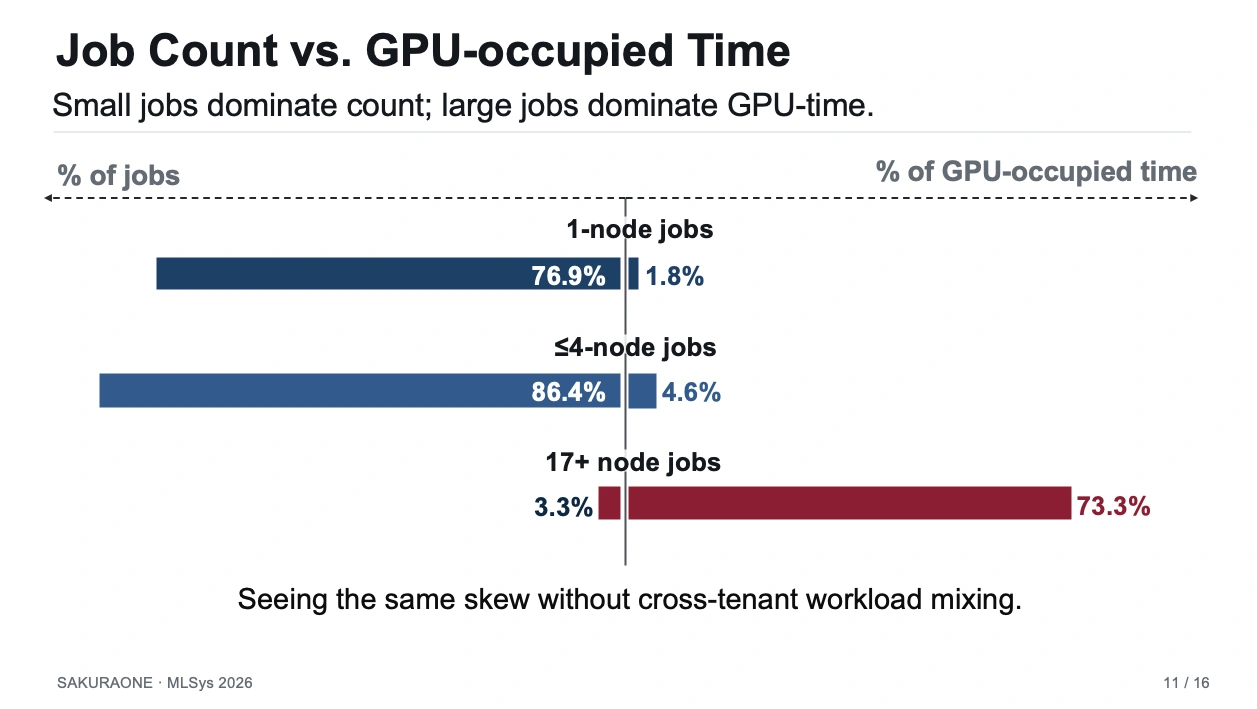
また、CANCELLED状態で終了したジョブがGPU占有時間の73.5%を占めるという結果についても紹介しました。これは単なる失敗や無駄な計算時間ではなく、ユーザーが学習曲線や検証結果を見ながら学習ジョブを途中で止める、LLM開発に特有のfeedback-drivenな運用の一部として解釈できるものです。
オーラル発表は12分という限られた時間での発表だったため、詳細なジョブ分類、GPU利用率、障害分析、RoCEv2のチューニングなどは論文本文で補足する構成としました。
発表後のQ&Aでは、さくらONEにおける他のLLM Trainingベンチマーク結果があるかどうかの確認や、ジョブのキャンセル数が多い傾向への興味をもらってもらったことが伺える質問がありました。Q&A時間は3分ほどの短い時間でしたので、ポスター発表にて詳細に議論する形になりました。

ポスター発表
ポスター発表は鶴田(@tsurubee3)が担当しました。セッションでは、以下のポスターを用いて研究内容の説明を行いました。
ポスターセッションは2時間で、その間に多くの参加者に立ち寄っていただき、研究内容について議論を交わしました。特に多く寄せられた質問は、LLM開発のワークロード特性に関するものでした。
「オーラル発表」で紹介したワークロード分析の結果は直感に反すると感じる方が多かったようで、聴講者からは「なぜこのようなことが起きるのか」という質問を多く受け、非常に興味深く受け止められている様子が伝わってきました。これに対しては、LLM開発ではデータセット構築やモデル評価など小規模ジョブも多く実行される一方で、今回のプロジェクトでは継続事前学習など1週間以上連続で回る大規模ジョブも存在したこと、また、LLM開発ではリソース利用の効率化のためにジョブの進捗を継続的にモニタリングし、有望でないジョブを積極的にキャンセルする運用が一般的であることなどを説明しました。
LLM開発では、ユーザーが学習過程に介入してジョブをキャンセルする運用や、開発フェーズごとに異なるジョブパターンへの遷移など、人とシステムが密接に連携する独特のダイナミクスが現れます。こうした実運用から得られた知見が学術コミュニティでも関心を集め、新鮮な視点を提供できることを実感できたのは、今後の研究開発を進めるうえでの大きな励みとなりました。
おわりに
MLSys 2026のIndustry Track新設は、本番環境での開発・運用知見を学術コミュニティに還元する重要な動きと言えます。私たちの発表も、当初は日本の一企業の実システムの事例ということもあり、どの程度関心を持ってもらえるか不安な面もありました。しかし、現地での活発な議論や質疑応答を通じて、産業界からの実運用知見が学術コミュニティで広く関心を持たれ、産業界と学術界をつなぐ場としてのIndustry Trackの意義を実感しました。今後さらに、機械学習システム研究と産業界の運用実践がより密接に結びつき、新たな研究テーマや実装上の知見が次々と生まれる場へと発展していくことが期待されます。
さくらインターネット研究所では引き続き、日本のAI研究・産業競争力を支える大規模AIインフラの研究開発に取り組んでまいります。本会議で得られた議論やフィードバックも、今後のさくらONEの発展と新たな研究課題の探索に活かしていきたいと考えています。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。