博物館用RAG(Retrieval-Augmented Generation)を作ってみました
皆さんこんにちは、さくらインターネット研究所の菊地です。
研究所ではAI・LLM(大規模言語モデル)技術に関して、技術そのものの発展のための本質的な研究からLLMを応用的に利用する研究まで、幅広く様々な領域での調査・検討を実施しています。今回はLLMを実際的に使う際にLLMに固有知識(ドメイン知識)を活用させるための手法として、汎用性があり使い勝手が良く近年注目されているRAG(Retrieval-Augmented Generation)を実際に試してみましたので、そのノウハウなどを簡単にご紹介したいと思います。
RAGとは?
LLMは、学習時点での情報を元に質問に対する回答を生成するため、学習時に含まれない固有情報(ドメイン知識、例えば会社の中でのみ公開される情報)についての質問をしても適切な回答は得られません。そこで、質問文に加えて、質問に関連するある程度まとまった量のドメイン知識をプロンプトに与えそれをLLMに読ませたうえで回答を生成させる、つまりLLMを情報整理マシンとして利用する、ということが考えられました。この様にドメイン知識を渡して回答の精度を高める仕組みのことをRAGといいます。
RAGは、その方法が提唱された2020年から、急激に様々な実現手法などが提唱・実装されてきており、現在も発展しつつある領域です。さくらインターネット研究所でも様々な応用例などについて注目していましたが、この度、さくらインターネット博物館というさくらインターネットのこれまでの歴史をまとめた資料館(のようなもの)を作ろうという話が持ち上がり、その固有情報をLLMで整理して取得できる手段(博物館AIさくらちゃん(仮称))が求められるようになったため、RAGによる自然言語対話システムを構築してみようということになり実際に試してみた、ということになります。
LLMおよびRAGについては様々な資料等が論文やWeb上で公開されていますので、本記事では詳細については割愛いたします。
RAGの構造
RAGの簡単な構造は次の通りです。RAGシステムでは、あらかじめドメイン知識をまとめたデータベースを作成しておき、それを検索できるようにしておきます(Step.0)。ユーザから質問文が与えられたら、質問文をもとにドメイン知識データベースを検索し関連するドメイン知識を取得します(Step.1)。そのドメイン知識と質問文を合わせてLLM(言語モデル、つまりは回答生成システム)に与え、得られた回答を最終的な質問に対する回答としてユーザに提示します(Step.2)。
RAGの作り方についても様々なやり方がありますが、今回はドメイン知識データベースについてはローカルのサーバ内(さくらのクラウドを利用)で構築・検索できるようにし、LLMについてはOpenAIのAPI呼び出しによりchatGPT-4o-miniモデルを利用して回答を生成するようにしました。RAGのシステム全体はPythonによるプログラムを作成して動かします。ドメイン知識データベースとしてクラウド上のサービスを利用することや、逆にLLMをローカルで動かすことなども可能です。それぞれの方式に一長一短があり(例えば費用や保存できるデータの量、また使い勝手など)、状況に合わせて適した方法を選ぶ必要があります。
RAG構築の実際
今回は、さくらインターネット博物館用としてさくらインターネットの古いホームページを取得した情報群がありますので、これをドメイン知識としてデータベースを構築します。ドメイン知識のデータベースを構築するのには、入力情報に対して埋め込み操作(embedding)という処理をしてそれをベクトルDBに格納します。embedding操作は上述のように例えばOpenAIのAPIを利用することやAzureのサービスを利用することなども可能ですが、今回はローカルで処理をするということで、Hugging FaceというオープンなAIプラットフォームのembedding model(intfloat/multilingual-e5-large)を利用します。また、ベクトルDBの構築にはFAISS(Facebook AI Similarity Search)というオープンソースの近似最近傍検索ライブラリを利用します。そしてこれらをまとめて利用するためにLangChainというオープンソースのフレームワークを利用します。
さくらインターネットの古いホームページ。ここからテキスト情報を抽出してドメイン知識として利用する
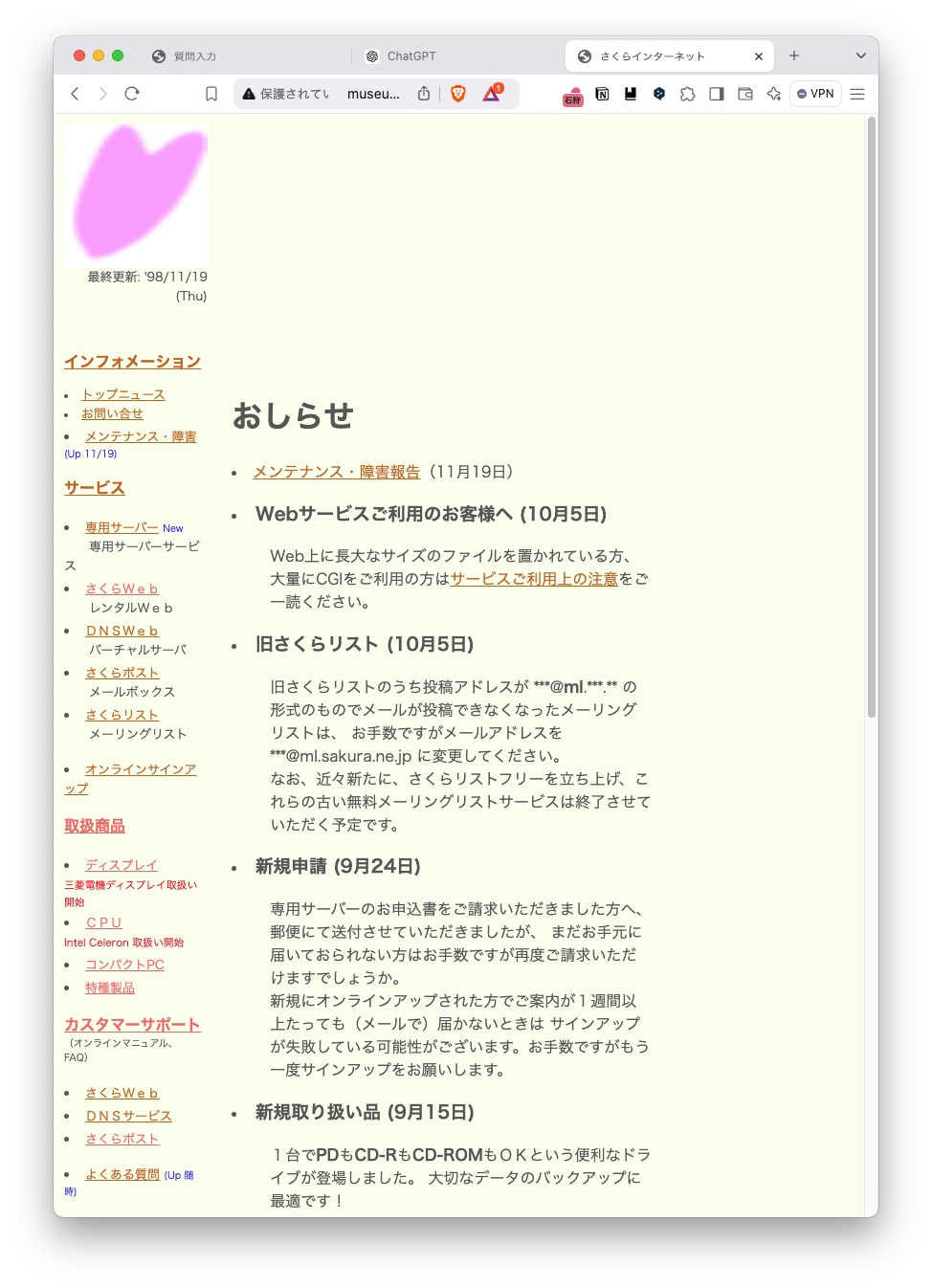
それぞれ下記に参照URLを示します。特にLangChainについては非常に更新が早く、使い方が頻繁に変わりますので注意が必要です。
- Hugging Face (intfloat/multilingual-e5-large) https://huggingface.co/intfloat/multilingual-e5-large
- FAISSについて: https://note.com/masuidrive/n/n5dc6da6dd2b6
- LangChainについて: https://qiita.com/finders/items/9befb7ae45cdbae2c925
ドメイン知識前処理(Step.0の前半)
以下は、カレントディレクトリを再帰的に検索し、htmlファイルからタグ情報を削除しテキストのみにして一つのファイルに纏めるpythonプログラムです。ベクトルDBを作成するためのデータの前処理のために利用します。
import os
from bs4 import BeautifulSoup
import chardet
def fetch_html_from_file(file_path: str) -> str:
# ファイルのエンコーディングを推定
with open(file_path, 'rb') as file:
raw_data = file.read()
result = chardet.detect(raw_data)
encoding = result['encoding']
# 推定されたエンコーディングでファイルを開く
try:
html = raw_data.decode(encoding)
except (UnicodeDecodeError, TypeError):
# デコードエラーが発生した場合、別のエンコーディングで試行する
try:
html = raw_data.decode('utf-8')
except UnicodeDecodeError:
try:
html = raw_data.decode('shift_jis')
except UnicodeDecodeError:
try:
html = raw_data.decode('iso-8859-1')
except UnicodeDecodeError:
# それでもエラーが解決しない場合、無理やりデコードする
html = raw_data.decode('utf-8', errors='replace')
return html
def remove_blank_lines(text):
lines = text.split('\n')
non_blank_lines = [line for line in lines if line.strip()]
return '\n'.join(non_blank_lines)
def download_and_process_html_files(root_directory):
documents = [] # 各HTMLファイルのテキストを格納するリスト
# 再帰的にディレクトリ内の .html ファイルを探索
for dirpath, _, filenames in os.walk(root_directory):
for filename in filenames:
if filename.endswith('.html'):
html_file = os.path.join(dirpath, filename)
try:
# HTMLファイルからコンテンツを取得
html = fetch_html_from_file(html_file)
# BeautifulSoupで解析
soup = BeautifulSoup(html, 'html.parser')
# テキストコンテンツを抽出
text = soup.get_text()
result_text = remove_blank_lines(text)
result_text += '\n\n'
# テキストをファイルに保存
output_file = os.path.splitext(html_file)[0] + '.txt'
with open(output_file, 'w', encoding='utf-8') as f:
f.write(result_text)
documents.append(result_text)
except Exception as e:
print(f"ファイル {html_file} の処理中にエラーが発生しました: {e}")
return documents
def save_documents_as_text_file(documents, output_file):
with open(output_file, 'w', encoding='utf-8') as f:
for document in documents:
f.write(document + '\n')
def main():
# カレントディレクトリ以下の全てのディレクトリを再帰的に探索
current_directory = os.getcwd()
documents = download_and_process_html_files(current_directory)
save_documents_as_text_file(documents, './output.txt')
if __name__ == "__main__":
main()このプログラムを実行することで、カレントディレクトリにoutput.txtというファイルが作成されます。
ベクトルDBの作成(Step.0)
上記のプログラムで作成したテキストファイルを読み込み、チャンクというパーツに分解してembeddingしDBに格納するlangchainベースのプログラムを以下に示します。このプログラムを実行することでベクトルDBが作成されます。
チャンクサイズとチャンクオーバーラップは検索性能(そして結果として回答の生成精度)に関係します。今回は、元データである一つ一つのhtmlファイルのサイズがだいたい1チャンクに収まるように、そしてLLMのプロンプトに与えることができるトークンの量を考慮して、5000を指定しました。
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# ベクトルDB化する元データファイル読み込む
with open("output.txt", encoding="utf-8") as f:
test_all = f.read()
# チャンクに分解する
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 5000,
chunk_overlap = 100,
)
texts = text_splitter.split_text(test_all)
# embeddingの指定
embedding = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
# 実際にembedding処理する
index = FAISS.from_texts(
texts = texts,
embedding = embedding
)
# 結果をfaiss_indexというディレクトリ下に保存する
index.save_local("faiss_index")なお、24MBのテキストファイルを処理するのに2コアのVMで2時間くらいかかりました。GPUを使える環境だともっと早く処理できるようです。
実際のRAG処理(ベクトルDB検索(Step.1)とLLMへの問い合わせ(Step.2))
ここまででドメイン知識のベクトルDB化ができましたので、あとはユーザからの質問文を受取り、その内容でベクトルDBを検索したうえでその結果とともにLLMにプロンプトとして入力するプログラムを作成します。UIが必要ですのでpythonベースのflaskを使用します。そしてLLM周りの処理についてはデータの前処理と同様にLangChainを利用します。コードを以下に示します。
# -*- coding: utf-8 -*-
from flask import Flask, render_template
from flask import request
from markupsafe import Markup
from markdown import markdown
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import os
openai_api_key = os.environ["OPENAI_API_KEY"]
embedding = []
index = []
def prepare_model():
# ベクトルDB検索のため、モデルとDB本体を用意する
global embedding
global index
print("loading HuggingFaceEmbeddings model...")
embedding = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
print("faiss_index loading...")
# ローカルディレクトリ配下のfaiss_indexからベクトルDBをロードする
index = FAISS.load_local("faiss_index", embedding, allow_dangerous_deserialization=True)
print("faiss_index loaded")
app = Flask(__name__)
@app.route('/', methods=['GET'])
def get():
# 質問文入力のためのフォームを用意
return render_template('form.html')
@app.route('/', methods=['POST'])
def post():
# フォーム内容(質問文)を受け取り、結果を出力する
# ここでRAGの本体の処理を実行する
global embedding
global index
query_content = request.form['content']
checkbox = request.form.get('checkbox')
# 質問文でベクトルDBを検索する
embedding_vector = embedding.embed_query(query_content)
doc = index.similarity_search_by_vector(embedding_vector, k=10)
# 使用するLLMを指定。OpenAIのgpt-4o-miniを使用する指定。
chat = ChatOpenAI(model="gpt-4o-mini", temperature=0, api_key=openai_api_key)
# システムプロンプトを指定
system = ("以下の情報を利用して、質問の文章に対する回答を作成して下さい。質
問に対して回答するのに十分な情報がない場合には、回答するのに十分な情報がない旨を返答して下さい。情報:{vectordb}")
human = "{input}"
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", human)])
chain = prompt | chat
result = chain.invoke(
{
"vectordb": doc,
"input": query_content,
})
# 結果の整形
md = Markup(markdown(result.content))
# 結果の出力
if checkbox == "debug_on":
# debugチェックボックスがonのときは、ベクトルDB検索結果とデバッグ情報も出力する
return render_template('response_with_debug.html', query_content = query_content, vectordb = doc, result = result)
else:
return render_template('response.html', query_content = query_content, result = md)
if __name__ == '__main__':
prepare_model()
app.run(debug=False, host='0.0.0.0', port=5000)やっている内容についてはプログラムを見ていただければだいたい分かると思いますが、質問文を受け取り、それをもとにベクトルDBを検索し、その結果をLLMに投げる、という処理です。LLMからはmarkdown形式で結果が返りますので、その整形処理もしています。
実行結果
実際に質問したところを見てみましょう。
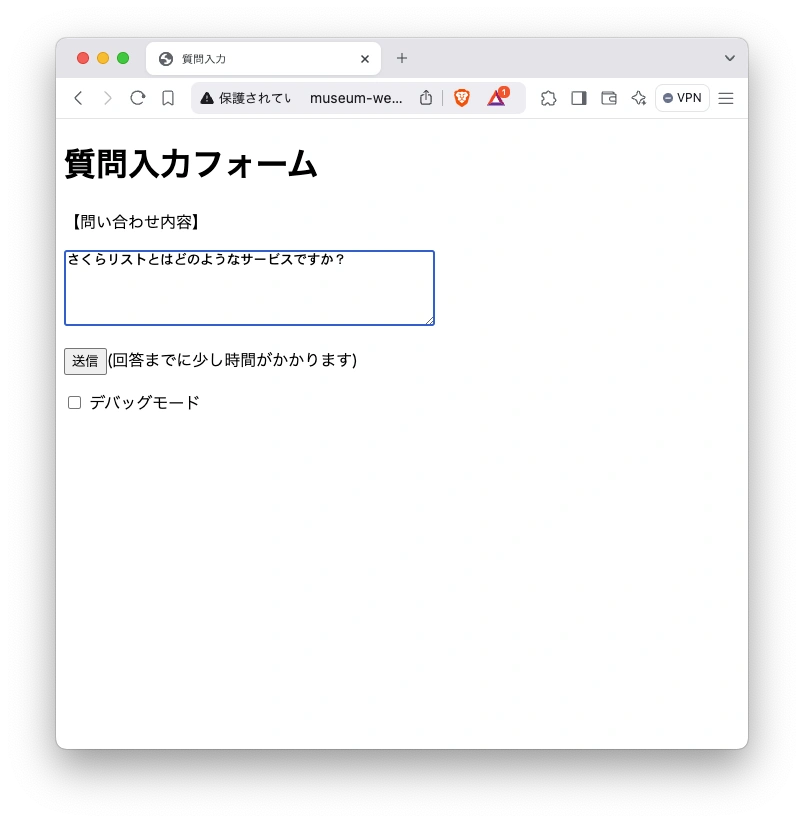
結果です。なお10秒くらいの実行時間がかかります。
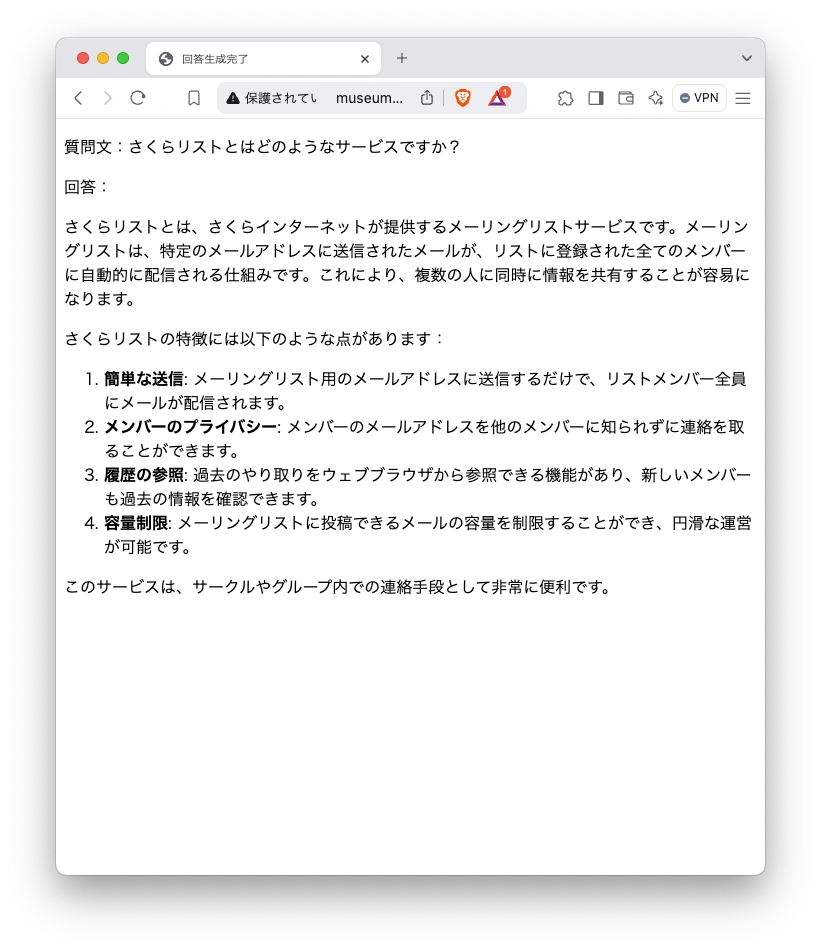
この様に、元のホームページに含まれる情報から回答が生成されていることがわかります。(さくらリストは現在すでにサービスを終了しており、同じ質問をchatGPTで質問しても同様の回答は得られません。)
まとめ
プログラムコード付きでだいぶ長くなってしまいましたが、この様にドメイン知識を利用するRAGを実装することができました。
LLMの利用方法はこれからも急速に発展することが予想されます。さくらインターネット研究所では今後も、LLM技術やその利用方法についての調査・研究を継続していく予定です。
著者
2017年4月入社。Edge/Fog Computing、分散系システム、IoT領域などの調査・評価・技術開発を担当。
新規サービスの登場や世の中の変化などを主に技術面から広く見ている。が、もともとの専門はネットワーク。