「AIトップカンファレンスからみるData-Centric AIの研究動向」についてData-Centric AI勉強会で発表しました
さくらインターネット研究所の鶴田(@tsurubee3)です。2025年1月27日に開催された第12回 Data-Centric AI勉強会にて、「AIトップカンファレンスからみるData-Centric AIの研究動向」というテーマで発表を行いました。本発表では、具体的な研究事例を取り上げながら、Data-Centric AIの重要性と最新の研究動向について紹介しています。
発表動画
私の発表は、動画の47分45秒あたりから始まります。
発表スライド
発表内容の紹介
以下、スライドの主要部分を抜粋して発表内容をご紹介いたします。
Data-Centric AIの重要性
本発表では、Data-Centricな取り組みが重要であることをいくつかの研究事例をもとに強調しました。その一つとして、CHI 2021でベストペーパーを受賞した『“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI』を紹介しました。

この研究では、データの問題が連鎖的に下流のプロセスや成果物に負の影響を及ぼしていく事象を「データカスケード」と定義しています。研究で特に強調されているのは、データ収集やアノテーションといったデータ関連の作業が、モデル開発と比較して軽視されがちという点です。その理由として、データ作業の成果は直接的な可視化や定量的評価が難しく、報酬や学術的成果などのインセンティブが不足していることが挙げられています。
例えば学術界では、これまで新しいモデルやアルゴリズムの提案とその性能の高さが最も重視され称賛される傾向にあり、データ作業の成果は論文として評価されにくい状況でした。この結果、データの品質管理に十分なリソースや注意が払われず、下流のプロセス全体に悪影響を及ぼすという負のサイクルが形成されていました。
ただし、2021年以降、この状況は大きく変化しつつあります。Data-Centric AIの普及により、データセットの構築や評価に関する研究の重要性が広く認識されるようになり、研究者にとってのインセンティブ構造も変化してきています。
学術界におけるData-Centricの潮流
本発表では、学術界におけるData-Centric AI関連の重要な出来事として、AI分野における最高峰の国際学会の一つであるNeurIPS(Neural Information Processing Systems)で2021年に新設された「Datasets and Benchmarks Track」について紹介しています。この新たなトラックの設立の経緯は、公式ブログ「Announcing the NeurIPS 2021 Datasets and Benchmarks Track」において詳細に説明されています。

このトラックの設立以降、データセットやベンチマークに関する研究の投稿数は顕著に増加しています。特に2024年には、前年比で大幅な増加を見せ、1820件もの研究がこのトラックに投稿されました。この顕著な投稿数の増加は、データセットやベンチマークに関する研究が、AI研究コミュニティにおいて重要な研究分野として認知され、活発化していることを示しています。このように、「Datasets and Benchmarks Track」の設立と発展は、これまでモデル開発に比べて学術的な評価を得にくかったデータ関連の研究に、新たな発表の機会と評価の場を提供しています。
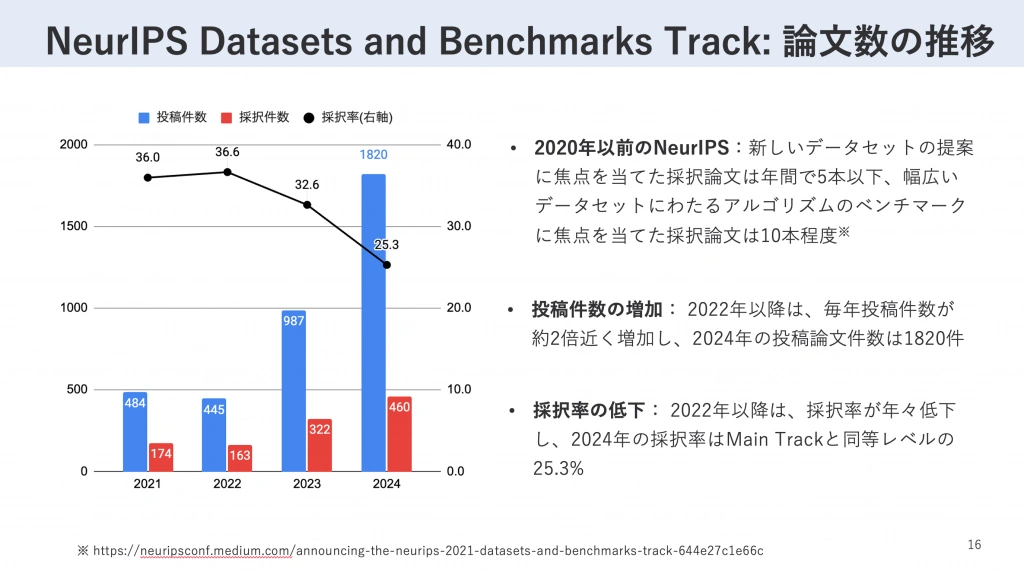
NeurIPS 2024からみる研究動向
本発表では、Data-Centric AIの研究論文を(1) Data-centric benchmark、(2) Training data development、(3) Inference data development、(4) Data maintenanceの4カテゴリに分類し、各カテゴリにおけるNeurIPS 2024の注目論文を紹介しました。ここでは、そのうちの2つの論文を紹介します。
一つ目に紹介する論文は、『DataComp-LM: In search of the next generation of training sets for language models』です。
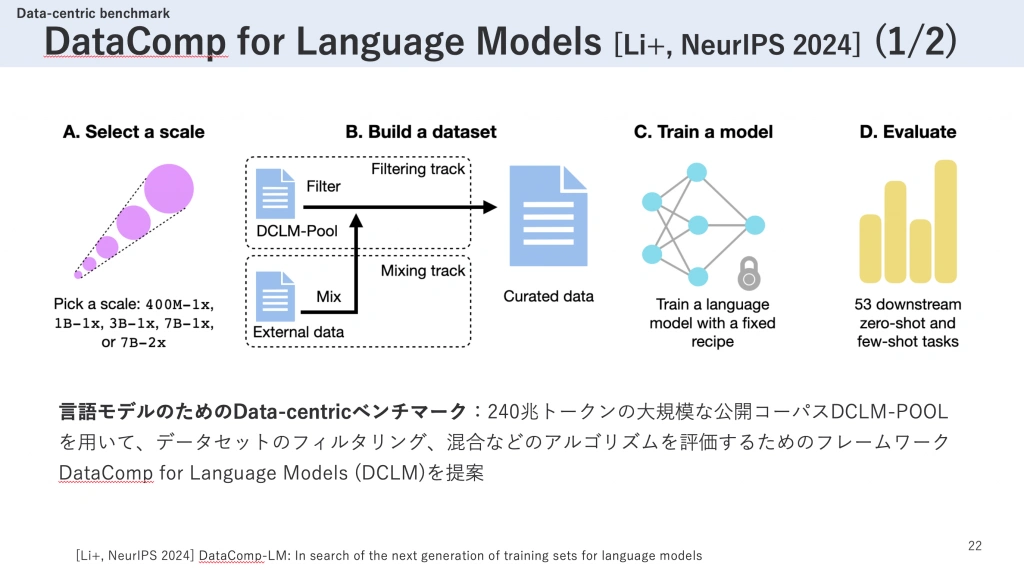
DataComp for Language Models (DCLM)は、言語モデルのためのデータセットのフィルタリングや混合などのアルゴリズムを評価するためのフレームワークです。この研究では、240兆トークンという大規模な公開コーパスであるDCLM-POOLを用いて評価を行います。
DCLMへの参加者は、まず最初にモデルのスケールを選択します。その後、2つのトラックのいずれかを選んで進めます。1つ目の「Filtering Track」ではDCLM-POOLからデータをフィルタリングし、2つ目の「Mixing Track」ではDCLM-POOLに独自のデータを混合することで、特定のサイズのデータセットを作成します。作成されたデータセットは、固定されたモデルアーキテクチャと学習条件のもとで事前学習が行われ、53個のダウンストリームタスクでその性能が評価されます。
このように、モデルと学習条件を固定した上でデータを変化させるData-Centricなベンチマークは、より効率的なデータキュレーションのアルゴリズム開発に活用できます。実際、この研究ではDCLMのFiltering Trackを用いて高品質なデータセットであるDCLM-BASELINEを構築し、その学習効率の高さを実証しました。
二つ目に紹介する論文は、『Not All Tokens Are What You Need for Pretraining』です。
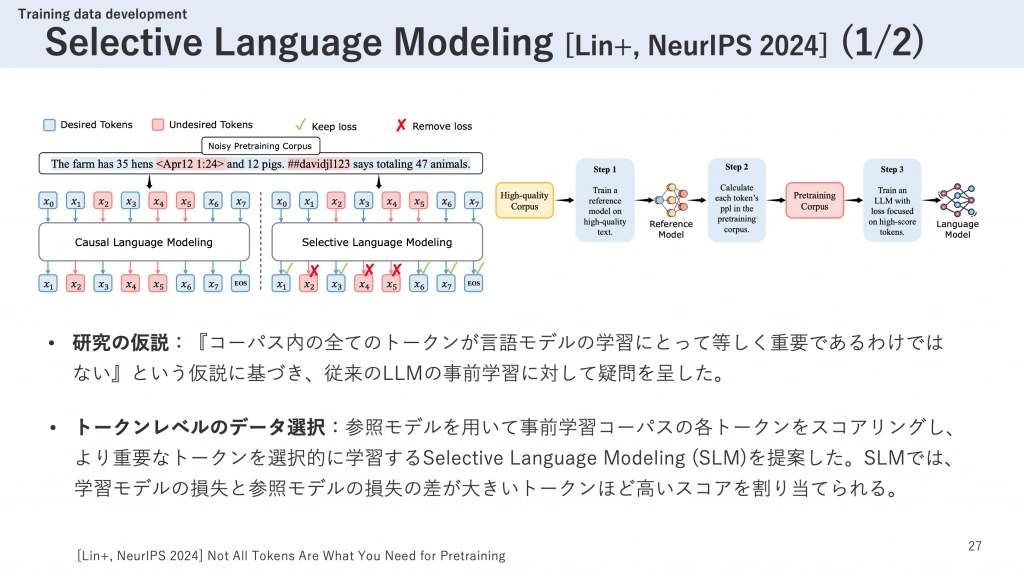
Selective Language Modeling (SLM)は、モデルの学習中にトークンレベルでデータを選択的に学習するという、独創的なアプローチを提案した研究です。
現在の大規模言語モデル(LLM)では、事前学習コーパスに含まれる全てのトークンに対してNext token predictionの損失を計算し、それをモデルのパラメータ調整に使用しています。これに対してこの研究では、「コーパス内の全てのトークンが言語モデルの学習にとって等しく重要であるわけではない」という仮説を立て、従来のLLMの事前学習手法に新たな視点を提供しています。
SLMの具体的な手法は以下の通りです。まず、高品質なコーパスを用いて参照モデル(実験では学習対象と同じアーキテクチャのモデル)を学習させます。次に、この参照モデルを使って事前学習コーパスの各トークンの予測損失を計算します。そして、学習対象のモデルのトークンの損失と、参照モデルの損失との差が大きいトークンほど重要であると判断し、それらが高い確率で学習対象として選択されるような手法を設計しました。
実験の結果、SLMを用いて学習したRHO-1モデル(1B)は、従来のベースラインモデルと比較して、わずか10分の1の学習トークン数でMATHベンチマークにおいて同等の性能を達成しました。これにより、SLMの高い学習効率が実証されています。
本発表では上記で紹介した二つの研究以外にも、興味深い研究成果を取り上げています。詳しい内容については、発表動画やスライドをご覧いただければ幸いです。
おわりに
第12回 Data-Centric AI勉強会で「AIトップカンファレンスからみるData-Centric AIの研究動向」について発表させていただく貴重な機会を頂戴し、ありがとうございました。多くの方々にご参加いただき、また様々なご質問を通じて参加者の皆様の高い関心に触れることができ、とても刺激になりました。このような素晴らしい機会を設けてくださった運営の皆様に感謝いたします。また機会がありましたら、ぜひ発表させていただければと思います。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。