NeurIPS 2024でAI創薬のためのデータセット構築について発表しました
さくらインターネット研究所・COGNANOの鶴田(@tsurubee3)です。2024年12月10日から15日にかけて、カナダブリティッシュコロンビア州バンクーバーで開催された「Neural Information Processing Systems (NeurIPS) 2024」にて、「A SARS-CoV-2 Interaction Dataset and VHH Sequence Corpus for Antibody Language Models」と題した研究を発表しました。本研究は、先日のニュースリリースでもお知らせしたさくらインターネットとCOGNANOによる共同研究成果です。
NeurIPS 2024 Datasets and Benchmarks Track
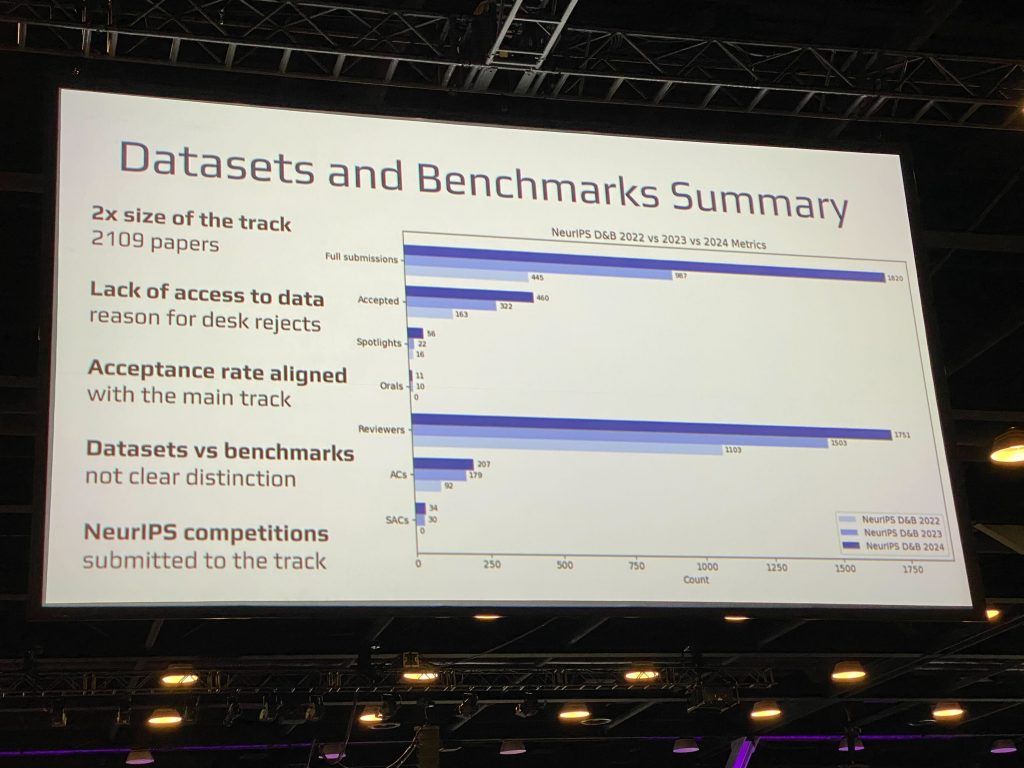
私たちの論文は、AI分野で最も権威ある国際会議の一つである「NeurIPS 2024」の「Datasets and Benchmarks Track」に採択されました。Datasets and Benchmarks Trackは、2021年に新設された比較的新しい研究トラックです。このトラックは、AIおよび機械学習分野の発展に不可欠な高品質なデータセットやベンチマークの設計・開発、さらにはデータ中心AIに関する研究を対象としています。この研究分野の注目度の高まりを反映し、2024年の投稿件数は前年比で約2倍に増加し、採択率は25.3%という厳しい競争率となりました。
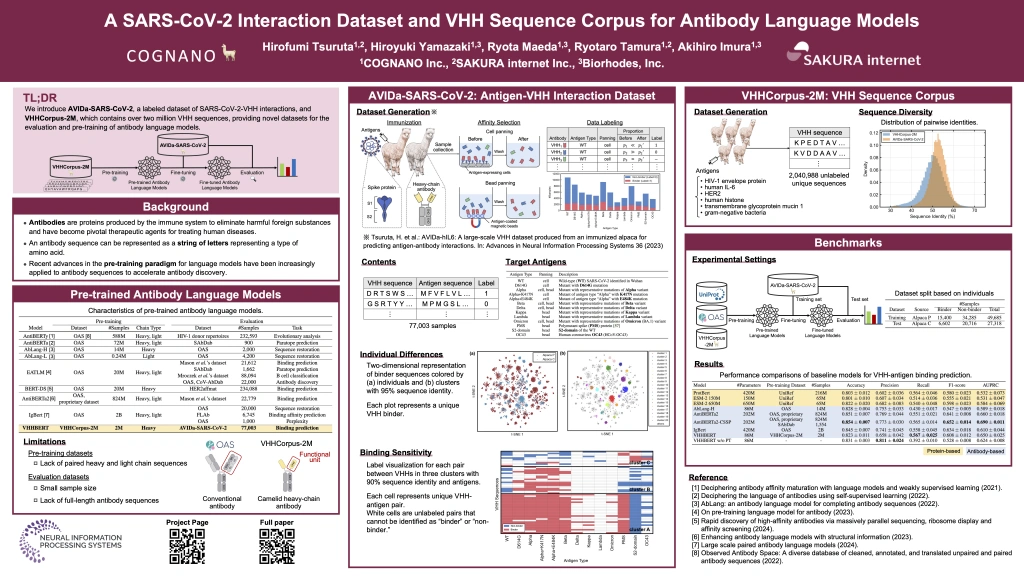
A SARS-CoV-2 Interaction Dataset and VHH Sequence Corpus for Antibody Language Models
鶴田博文1,2, 山崎寛章2,3, 前田良太2,3, 田村龍太郎1,2, 伊村明浩2,3 [論文] [コード]
1. さくらインターネット株式会社 2. 株式会社COGNANO 3. 株式会社ビオロドス
研究概要
私たちの研究は、AIによる新薬開発、特に抗体医薬品の設計を加速させることを目指したものです。近年、ChatGPTに代表される言語モデルの技術が大きく進展していますが、この技術を抗体の設計に応用することで、効率的な医薬品開発が可能になると考えています。
本研究では、主に2つのデータセットを開発・公開しました。
- VHHCorpus-2M:抗体言語モデル(Antibody Language Models)を事前学習するための抗体配列データセット
- AVIDa-SARS-CoV-2:新型コロナウイルス(SARS-CoV-2)に対する抗体の有効性を予測・評価するためのデータセット
これらのデータセットは、言語モデルの技術を活用して、効果的な治療用抗体を効率的に設計するための基盤となることが期待できます。特に、本研究では抗体言語モデルのSARS-CoV-2への応用可能性を示した点で、実用的な意義も大きいと考えています。
より詳細については、以下のブログで解説しているので、興味のある方はぜひご覧ください。
https://research.sakura.ad.jp/2024/11/14/neurips2024-paper-introduction/
ポスター発表
研究発表は、現地時間2024年12月13日の16:30から19:30に行われたポスターセッションにて実施しました。セッションでは、以下のポスターを用いて研究内容の説明を行いました。
当日のポスター発表では、3時間のセッションを通して、世界中の研究者から途切れることなく質問や議論が寄せられました。特に、データセットの構築方法や応用可能性について、多くの方々から関心を持っていただき、活発な議論ができました。


発表を終えての感想
2024年のAlphaFoldのノーベル賞受賞が示すように、タンパク質と機械学習の融合は、現在最も可能性を秘めた研究領域の一つとして注目を集めています。実際に、NeurIPS 2024の6つのポスターセッションすべてにおいて、創薬やタンパク質に関する研究発表が行われ、多くの研究者の関心を集めていた点が印象的でした。このような世界的な潮流の中で、世界最高峰の国際会議であるNeurIPSにて私たちのAI創薬研究を発表できたことは、研究の方向性が時代の要請に応えるものであることを実感させてくれました。
また、ポスター発表を通じて、世界各国の研究者との直接対話の機会を得られたことは、非常に貴重な経験となりました。特に、私たちが提案したデータセットの応用可能性について、多くの研究者から示唆に富むフィードバックをいただけたことは、研究の新たな展開を考える上で大きな刺激となりました。この経験を糧に、より実用的で価値のある研究成果を生み出せるよう、引き続き研究開発に邁進していく所存です。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。