言語モデルを用いたAI創薬:NeurIPS 2024採択論文の解説
さくらインターネット研究所の鶴田(@tsurubee3)です。先日、『さくらインターネットとCOGNANOのAI創薬に関する共同研究論文が、世界最高峰のAI国際会議「NeurIPS 2024」に採択』というニュースリリースを公開しました。このNeurIPS 2024に採択された論文(以下、「本論文」)は、ここ数年で急速に発展している言語モデルを創薬分野、特にタンパク質のアミノ酸配列に応用する研究です。このような研究は、Metaのようなビッグテックも活発に取り組んでおり、自然言語処理の分野で培われた技術が、自然言語の枠を超えて新薬候補の探索や設計に利用されつつあります。本記事では、本論文を中心に、言語モデルを活用した創薬の研究についてご紹介します。
研究の概要
まず、本論文の全体像を示す下の図に沿って、研究の概要を説明します。
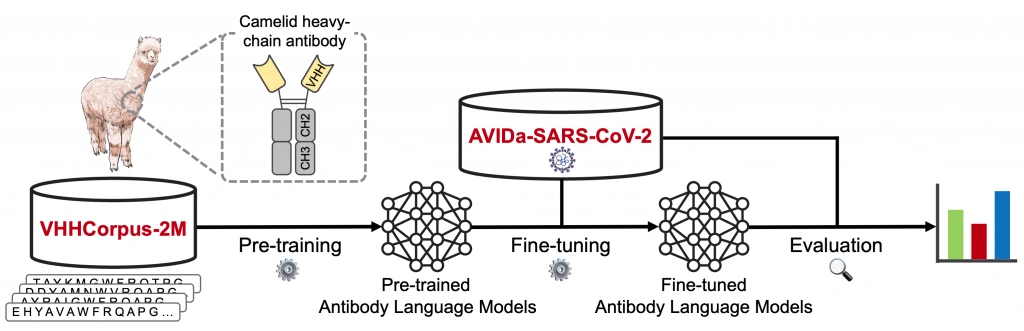
本論文では、抗体言語モデル(Antibody Language Models)を事前学習するための抗体配列データセット「VHHCorpus-2M」と、事前学習した抗体言語モデルを評価するためのデータセット「AVIDa-SARS-CoV-2」を提案・公開しました。本研究の特徴の一つは、高品質かつ大量の抗体データを創出するためにアルパカという動物を利用した点です。もう一つは、2020年初頭から世界的なパンデミックを引き起こし注目された新型コロナウイルス(SARS-CoV-2)に対する有効な抗体探索を目的としたデータセットを提案した点です。各キーワードについては順を追って解説します。
抗体とは
抗体は、体内に侵入したウイルスや細菌などの有害な異物(これを「抗原」という)を排除するために、免疫システムによって生成されるタンパク質です。この抗体を利用して病気の予防や治療を行う薬が抗体医薬であり、抗体は現在、ヒトの病気を治療するための重要な創薬モダリティの一つとされています。
抗体の配列データ
前述のとおり、抗体はタンパク質であり、タンパク質は1文字のアルファベットで表される20種類のアミノ酸が鎖状に並んだ「アミノ酸配列」、つまり文字列として表現できます。たとえば、R Y A V A W…といったアミノ酸の並び順が重要であり、この順序によって構造や機能が変化します。このため、抗体は語彙サイズが20に限定された自然言語のようなデータとして捉えることができます。この性質から、抗体配列を活用した言語モデルの開発が盛んに進められています。
アルパカの特殊な抗体
我々がデータ生成に利用しているアルパカは、抗体配列データの蓄積に適した特性を持っています。以下に、ヒトとアルパカの抗体構造の違いを簡単に示します。
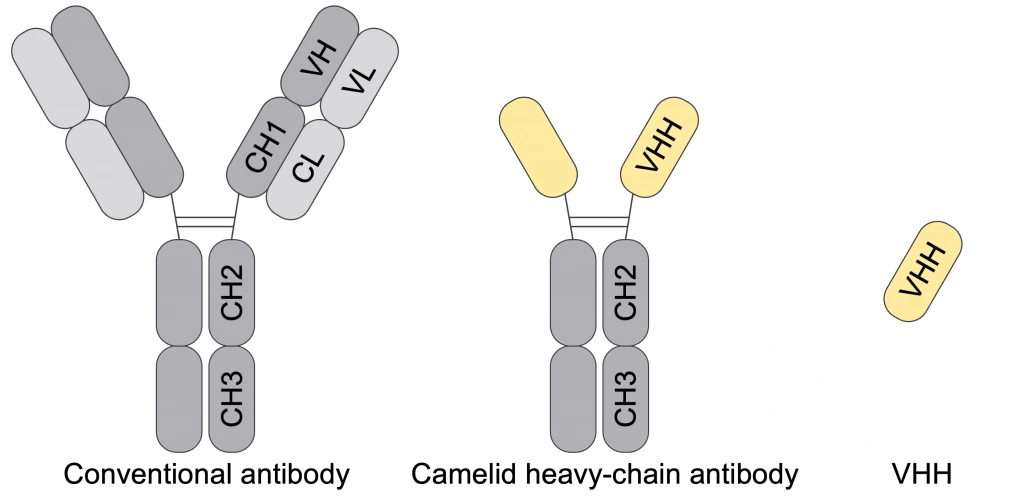
ヒトやマウスなどが持つ抗体(上図の「Conventional antibody」)は、2本の重鎖と2本の軽鎖で構成されており、重鎖と軽鎖のペアが標的となる抗原に対する機能単位として働きます。そのため、抗体配列データとしては、重鎖と軽鎖のペア配列を含むことが理想的です。しかし、このペア配列の取得には時間と手間を要するバイオ実験が必要であり、大規模なペア配列データベースの構築は困難です。実際、代表的な抗体配列データベースであるObserved Antibody Space (OAS)には、20億以上の非ペア抗体配列(重鎖のみまたは軽鎖のみ)が収録されていますが、ペア配列はその1/1000以下の数しかありません。
一方、アルパカやリャマなどのラクダ科動物は、重鎖のみからなる抗体(上図の「Camelid heavy-chain antibody」)を持ち、その可変領域はVHH(またはNanobody)と呼ばれています。VHHは単一の機能単位として作用するため、その配列には抗原に対する抗体の機能に必要な情報がすべて含まれています。このシンプルな構造により、VHHは他の抗体に比べて効率的にアミノ酸配列をデータ化できます。
抗体言語モデル
Metaの研究チームは、タンパク質のアミノ酸配列からその構造や機能を予測する言語モデル「ESM(Evolutionary Scale Modeling)」を開発しています。これらのモデルは自然言語処理の技術を応用し、大規模なタンパク質配列データを学習することで、タンパク質の特性を高精度に予測することを目指しています。これらの研究に触発され、タンパク質のサブセットである抗体に特化した言語モデルの構築が進められています。下表に代表的な抗体言語モデルをまとめています。
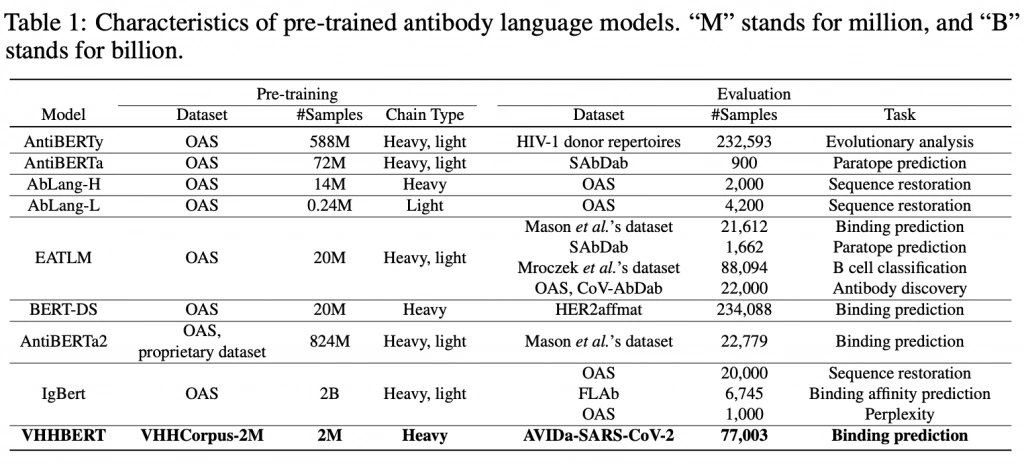
これまでに多くの研究チームが独自の抗体言語モデルを開発してきましたが、その多くはOASを用いた非ペア抗体配列で事前学習されています。また、評価用データセットにはデータ数が非常に少ないものや、抗体の全長配列が含まれていないなど、いくつかの制約があります。これらの課題を解決するために、私たちはアルパカ由来の抗体であるVHHを用いた新しい事前学習用および評価用のデータセットを提案しました。
VHHCorpus-2M: 抗体配列コーパス
VHHCorpus-2Mは、5頭のアルパカから収集した2,040,988件のユニークなVHH配列を含むコーパスです。多くの既存の抗体言語モデルは、BERTベースのモデルをMasked Language Modelingで学習しています。これに倣い、VHHCorpus-2Mを用いて86MパラメータのRoBERTaベースモデル「VHHBERT」を構築し、Hugging Face Hubで公開しました。
AVIDa-SARS-CoV-2: 抗体とSARS-CoV-2の相互作用データセット
AVIDa-SARS-CoV-2は、SARS-CoV-2を免疫した2頭のアルパカから収集した77,003件のデータサンプルで構成されるSARS-CoV-2-VHH相互作用データセットです。このデータセットには、22,002件の結合ペアと55,001件の非結合ペアが含まれています。以下に、AVIDa-SARS-CoV-2が抗体言語モデルの評価、ひいては創薬応用において有用であることを示す特徴を、二つの観点から紹介します。
SARS-CoV-2の変異の効果
新型コロナウイルスのパンデミックが示したように、ウイルスはヒトの免疫システムを回避するために変異を通じて絶えず進化します。こうした変異によりアミノ酸配列が一部変化し、わずかな変化でも抗体との結合に大きな影響を及ぼすことが知られています。そのため、抗原の変異が抗体結合に与える影響を予測することは、治療用抗体の開発において重要です。AVIDa-SARS-CoV-2では、SARS-CoV-2の野生型(WT)に加え、Alpha、Beta、Delta、Omicronなど12種類の代表的な変異株やヒトコロナウイルスOC43を標的抗原とし、これらの抗原と多様なVHHとの結合能力をデータ化して、機械学習モデルに変異の影響を学習させるためのデータセットを構築しました。下図は、配列一致度が90%以上の3つのVHHクラスターが各抗原に結合するかどうかを可視化したものです。
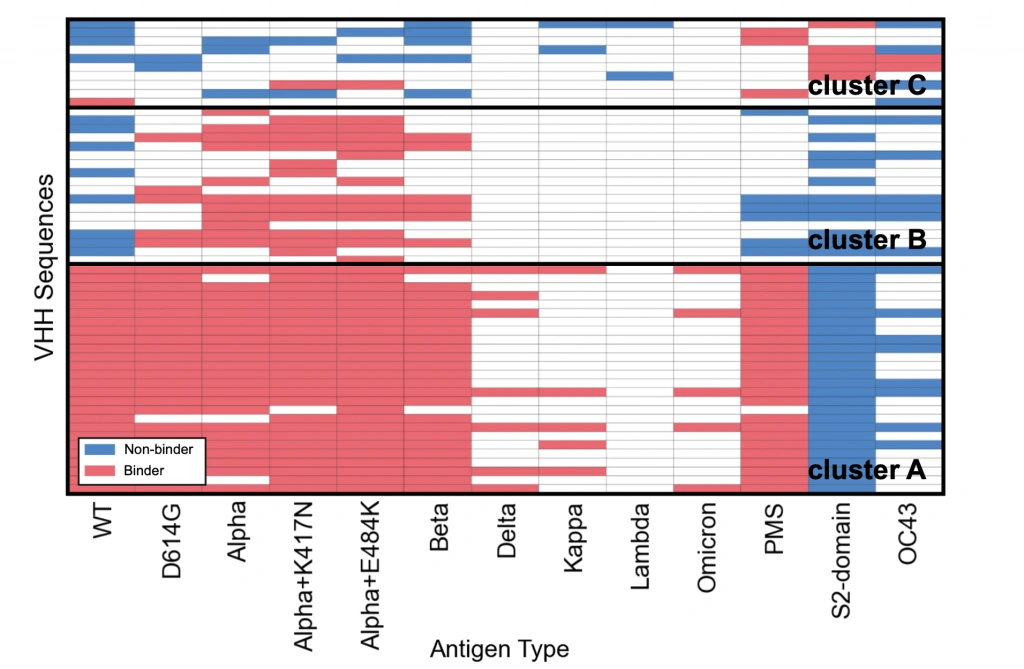
各行は同一のVHH配列の結合能力を示し、赤が結合、青が非結合、白が結合か非結合か不明であることを示しています。興味深いことに、図中最下部の「cluster A」の多くのVHHは、WTからBetaまでの抗原には結合しますが、Delta、Kappa、Lambda、Omicron株には結合しません。これは実世界で観察される免疫回避の現象を反映しています。このように、抗原のわずかなアミノ酸変化が抗体の結合可否に影響を与えるセンシティブなデータは我々の知る限り他に例がなく、この特徴は抗原変異が抗体結合に与える影響を理解する上で貴重な知見を提供しています。
SARS-CoV-2特異的抗体の個体差
AVIDa-SARS-CoV-2は、SARS-CoV-2を免疫した2頭のアルパカの体内で生成された抗体をデータ化しています。このデータを用いて、異なる個体の免疫システムがSARS-CoV-2に対して生成した抗体がどの程度異なるか、もしくは似ているかを分析しました。下図は、2頭のアルパカそれぞれから得られたSARS-CoV-2結合抗体配列をアミノ酸の物理化学的性質に基づきエンコードし、次元圧縮して2次元マップに可視化したものです。左図は個体ごとに、右図は配列一致度95%以上のVHHクラスターごとに色分けしています。
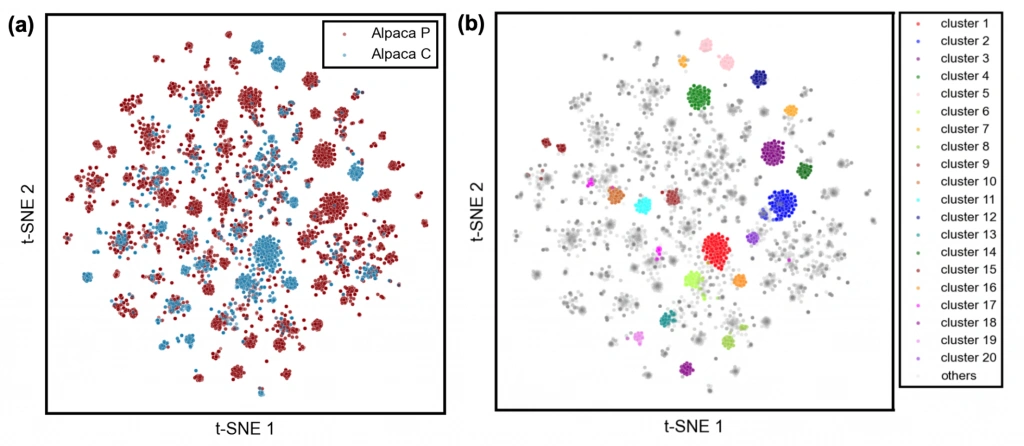
左図から、各個体から得られたVHH配列は部分的に重なっているものの、主に異なる領域に集約されていることがわかります。また、右図は、この2次元空間での集約が配列一致度に基づいて形成されたVHHクラスターを反映していることを示しています。例えば、赤色の「cluster 1」はAlpaca Cから生成されたVHHで構成されており、一方、青色の「cluster 2」はAlpaca Pから生成されたVHHで構成されています。これらの結果は、データセット生成に複数の個体を使用することで、抗原特異的なVHH配列の多様性を高める効果があることを示しています。
ベンチマーク実験
本論文では、提案したデータセットを用いたベンチマーク結果を報告しています。ベースラインモデルとして、既存のタンパク質言語モデル(ProtBert、ESM-2)、抗体言語モデル(AbLang、AntiBERTa2、IgBert)、およびVHHCorpus-2Mで独自に学習した抗体言語モデル(VHHBERT)を使用し、下表に示すように性能の比較評価を行いました。
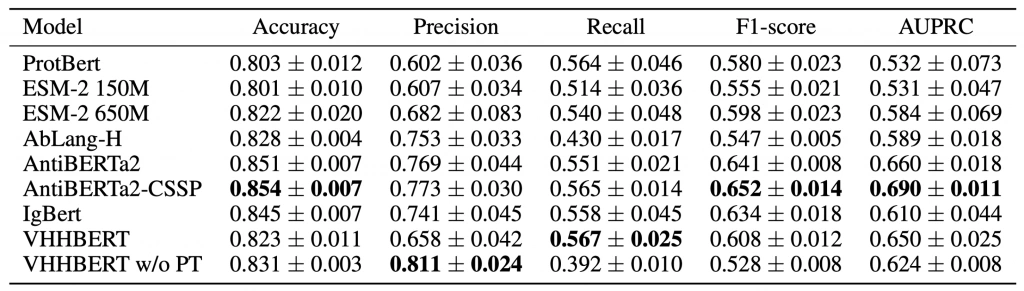
本記事では、この実験の詳細な設定や結果の考察は割愛しますが、AVIDa-SARS-CoV-2が抗体言語モデルの性能評価において貴重なベンチマークを提供し、今後のAI創薬の発展に貢献する可能性を示しました。
さいごに
本記事では、NeurIPS 2024に採択された論文をもとに、抗体創薬と言語モデルの融合領域に関する最新の研究をご紹介しました。この分野は、大規模言語モデルの開発で培われた技術が今後さらに取り入れられ、大規模な開発競争が予想される注目の領域です。より詳しい内容にご関心のある方は、ぜひarXivに公開されている論文をご一読ください。
著者
2019年8月入社。創薬、材料科学、システム運用等の分野における機械学習・人工知能(AI)技術の研究を担当。
学生時代は材料工学を専攻し、高分子材料の物性に関する研究に従事。2012年9月に修士課程を早期修了。2016年11月にIT業界に飛び込み、機械学習エンジニア、インフラエンジニアを経て、現職に至る。AI創薬のためのデータセット構築に関する主著論文が、AI分野で世界最高峰の国際会議であるNeurIPS(Neural Information Processing Systems)2023および2024のDatasets and Benchmarks Trackに2年連続採択。