高遅延環境でのPercona XtraDB Clusterの振る舞い
こんにちは、さくらインターネットの鷲北です。
Percona XtraDB Clusterを試す という記事では PXC を構築して動作させる手順を示したわけですが、これを使って実験をしてみたいと思います。まずは背景について説明していきましょう。
背景
ゆううきさん は エッジコンピューティングを生かしたウェブアプリケーションホスティング構想 という記事で、エッジコンピューティング環境下においてウェブアプリケーションがどのような課題をもつかについて論じています。そしてその中で、通信レイテンシ(遅延)の大きな(25ms-50ms)環境下においてデータベースが受ける影響について触れています。
本稿で取り上げたいのは、ウェブアプリケーションの構成パターンについて論じているところで示された、「3-tier構造をすべてエッジに配置、かつリーダーレスである構成」の例です。
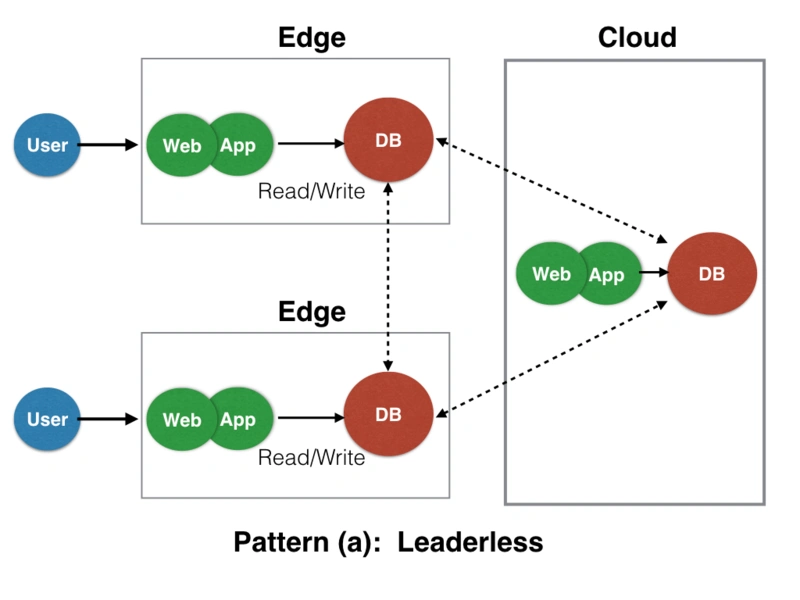
ゆううきブログ 図1より一部引用
このようなリーダーレスなデータベース・クラスタを構成するには、PXCはうってつけと言え、環境を簡単に構築することができます。またさくらのクラウドは東京と石狩にゾーンを持ち、その間を繋ぐ回線もあって、比較的大きな遅延も実現(?)できます。上図を模した実験環境を再現することができるのではないかと考え、実行したのが本稿です。
実験環境
実験にあたっては、次のような環境を準備しました。
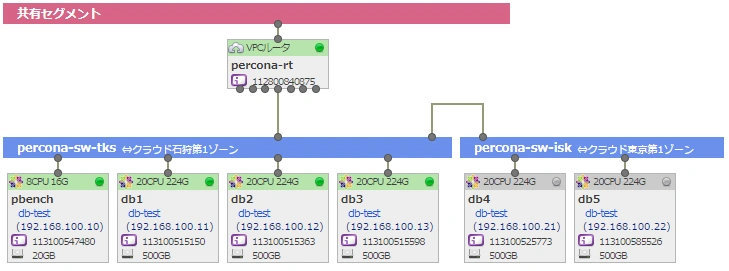
実験環境ネットワーク図
さくらのクラウドの東京・石狩ゾーンにそれぞれセグメントを用意し、両方をブリッジ接続します。そして東京にベンチサーバを置き、PXCクラスタを構築します。まず東京で3台のクラスタの実験を行い、つづいて1台を石狩のサーバで置換、最後に2台を置換するという順序で実験をします。これによりゆううきさんが示したクラウド/エッジ間の遅延をエミュレートしてみました。
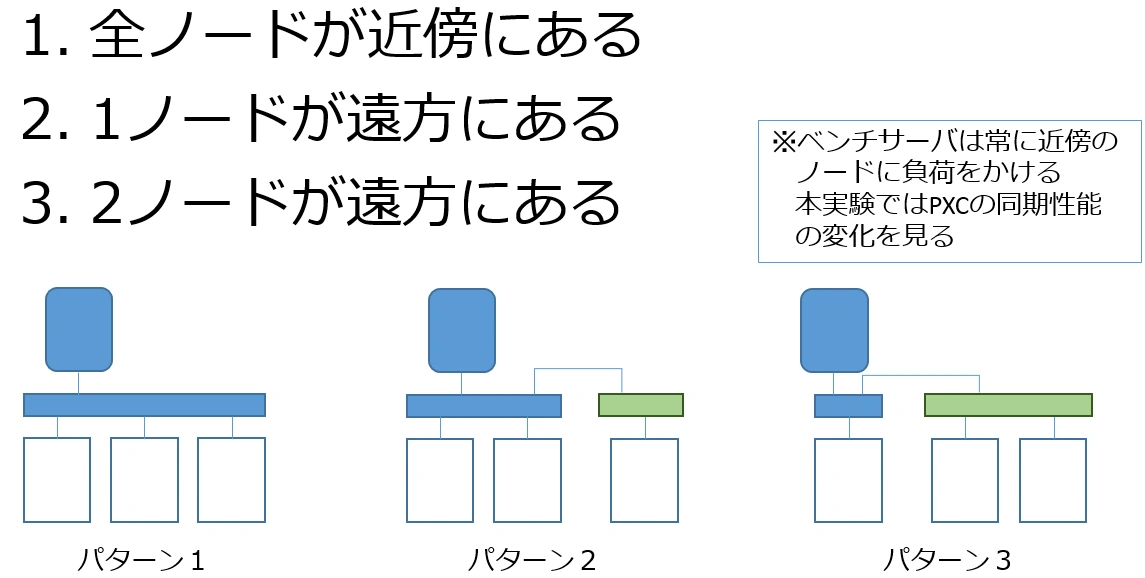
上記のような構成では三角の構成は正しく再現できていませんが、少なくともPXCのmaster/master構成において高遅延が発生している場合、どのように振舞うかは観測できると期待できます。
実験サーバのスペックとPXCの設定
実験サーバは次のようなスペックで用意しました。
コア数 | 20core |
メモリ | 224GB |
ディスク容量 | 1TB |
PXCの設定はあまりいじっていません。
- wsrep_slave_thread=100
設定してみたものの大きな差異は出ていないような気がします
MySQLの設定は以下の通りです。
[mysqld]
# max connections
max_connections=300
max_prepared_stmt_count=1000000
# thread cache
thread_cache_size=300
# query cache
#query_cache_size=512M
#query_cache_limit=16M
#query_cache_type=1
query_cache_type=0
query_cache_size=0
# file per table
innodb_file_per_table=ON
# buffer size
innodb_buffer_pool_size=180G
innodb_log_file_size=4G
innodb_flush_log_at_trx_commit=1
innodb_flush_method=O_DIRECT
sort_buffer_size=1M
read_buffer_size=512K
read_rnd_buffer_size=1M
skip-name-resolveベンチーマークツール
ベンチマークはsysbenchで行いました。コードを https://github.com/akopytov/sysbench から取得し、コンパイルして利用しました。
ベンチに当たってはテーブル数100、テーブルサイズ100万とし、DBサイズはメモリに収まる程度にしています(Disk I/Oによる影響を排除するためです)。
ベンチマークにあたっては次のようなバッチを使いました。
time=900
for threads in 1 2 4 8 16 32 64 128 256; do
sysbench \
--db-driver=mysql \
--mysql-host=$DBHOST \
--mysql-db=$DBNAME \
--mysql-user=$DBUSER \
--mysql-password=$DBPASS \
--threads=$threads \
--time=$time \
--tables=$NUM_TABLES \
--table_size=$TABLE_SIZE \
--report-interval=1 \
oltp_read_write \
run
done実際にはprepareなどいろいろあるんですが、細かい話は省略いたします。
計測結果
では計測結果を見ていきましょう。まず東京/石狩間のレイテンシの実測結果です。
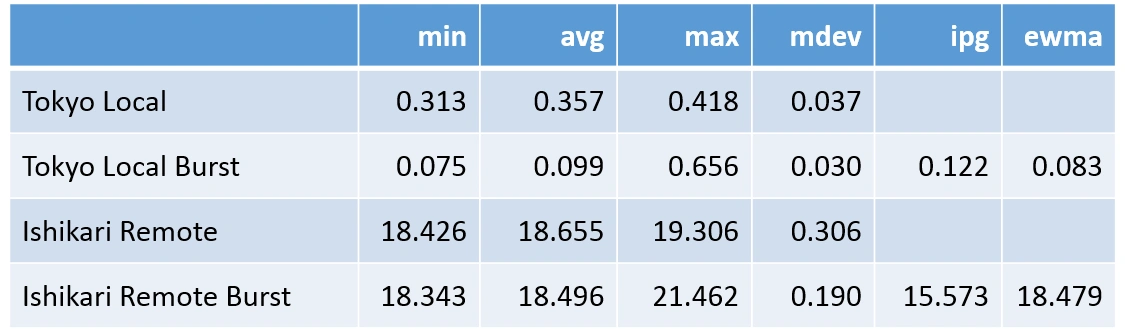
東京/石狩間のpingによる測定結果
上記はpingコマンドによるRTTの測定結果を比較したものです。1秒毎に10回実施した結果と、1000回バーストとを比較しています。おおよそですが、ローカル環境のRTTは1秒毎のpingで0.3ms、バーストで0.1ms程度。東京/石狩間のRTTは18.5ないし18.6msとなりました。その比率は最大で180倍に及ぶということです。この遅延は、冒頭でゆううきさんが示したエッジ・コンピューティングが示した課題の遅延「25ms-50ms」に比べると若干良い条件になっています。
以上の条件下でsysbenchを実施し、1秒毎に結果をプロットしたものを時系列にプロットしました。それが下図です。
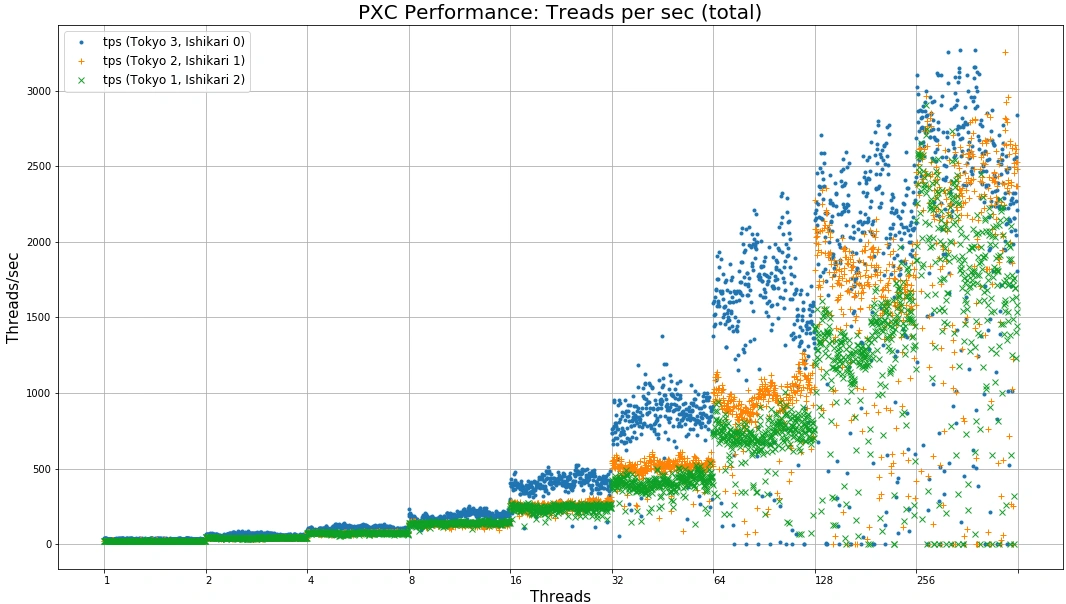
並列度ごとの秒間処理スレッド数
この図は、横軸に並列度(1、2、4…256まで)と上げていくごとに、処理できるスレッド数(トランザクション数と考えていただいて結構です)が変化する様子をプロットしています。
この図で着目していただきたいのは、16並列のあたりで3ノードともローカルにある場合に性能差が現れ始め、32並列、64並列において顕著になっているということです。これはノード間遅延が大きいとき、PXCがwriteリクエストを受けると全ノードが同期を待つまでの遅延も大きくなるため、徐々に性能差も顕著化するのだと考えられます。一方並列度が128、256になると、サーバ性能がサチって差がなくなってきてしまいます。
並列度ごとの、スレッド当たりの秒間スレッド処理数にプロットしなおしてみましょう。
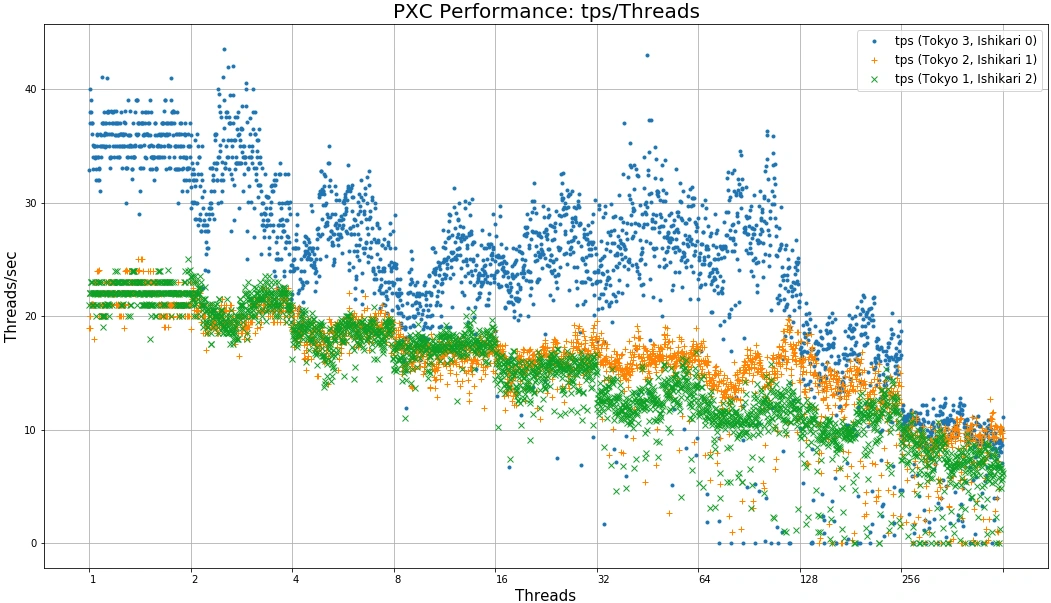
並列度ごとの処理スレッド当たり秒間処理数
この図は、縦軸の処理数を並列度で割っています。このためPXCの処理スレッドあたりの処理性能がどのように変化しているかがわかります。ローカルネットワーク通信環境の方がクラウド/エッジ間通信を模した高遅延ネットワーク通信環境に比べて1.5倍ほど性能がよいように見えます。また128並列を超えるとサチっていることも一目瞭然でしょう。
最後に、Percona Monitoring and Management を使って測定したPXCクラスタ内部の様子をご覧に入れましょう。下に示した図は、Galeraクラスタの遅延を示したものです。左の山がパターン1(全ノードがローカル)、真ん中がパターン2(1つが石狩)、右の山がパターン3(2つが石狩)です。
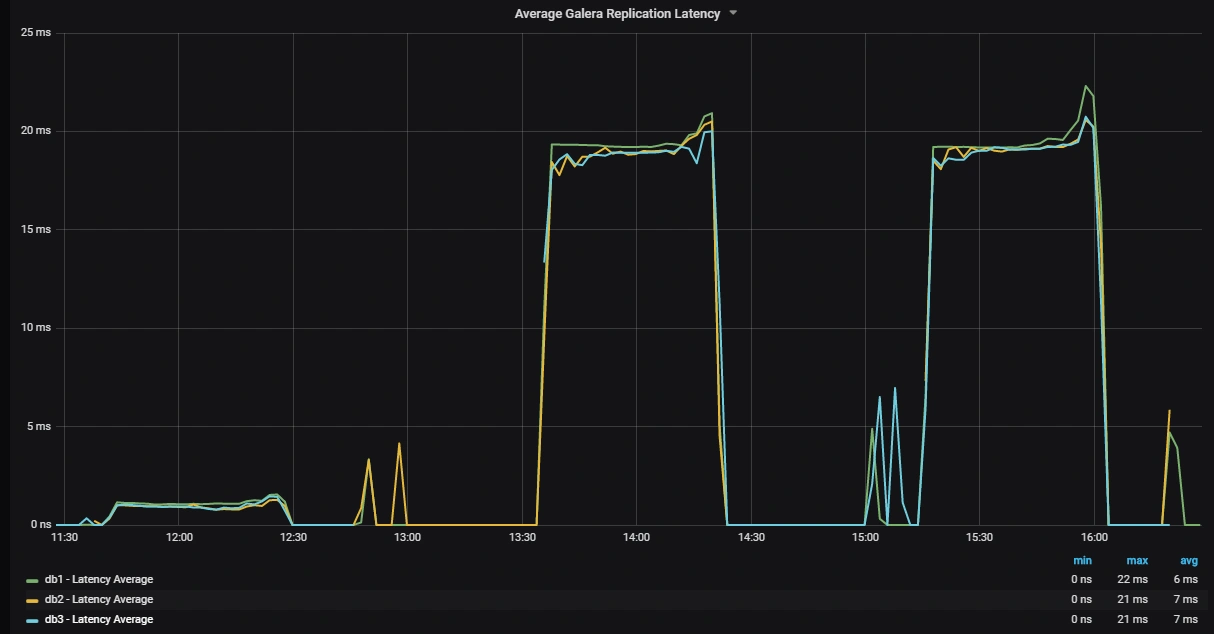
PMMによるPXC(Galera)レプリケーション遅延の推移
これでみるとGaleraのレプリケーションは、一番遅いノードにあわせて遅くなるのだということ、通信遅延がほぼそのままレプリケーション遅延に比例しているということが分かります。
考察
以上、PXCの3ノード構成で、通信遅延が性能にどのような影響を与えるかを実験して確かめてみました。簡素な実験でしたが、一定の影響があることが測定できました。
- 18ms前後の遅延によって、sysbench指標でおよそ1.5倍の性能差が観測された
- 遅延差186倍に対してsysbench指標の差が大きいのか否か判然としない
- たとえば25msや50msといった環境下でsysbench結果がどうなるかを調べ、比較する必要がある(が容易でない)
- PXCのmaster/masterは、replicationと異なりフローコントロールを含むデータ同期機構を備えている
- データが同期するまでスロットリングがかかることを観測できた
- ただし本稿では書き込んだデータが正しく書けたかverifyは行っていない
- もうちょっとマジメにDBチューニングしないといかん
実験結果の考察は以上です。
PXCは優秀なデータベースで、簡単な運用でmaster/master環境が手に入る点が魅力的です。しかしメリット・デメリットをきちんと理解しないと、十分な性能が得られなかったり、システムに不具合が生じる可能性があります。特にWrite Heavyアプリケーションでは急激に性能が悪化することが考えられ、このようなケースに特効薬はないということを理解していただきたいと思います。一方、Read Heavyアプリケーションであれば一定の性能が見込まれると考えます。
参考リンク
著者
1998年、エス・アール・エス有限会社入社の後、合併を経てさくらインターネット株式会社へ。技術部部長、取締役を経て、2009年7月に研究所所長就任。
会社設立時より技術担当。レンタルサーバ組み立てから始め、データセンタ構築、バックボーン構築、オンラインゲームプロジェクトの技術運用などを歴任。2018年まで、クラウドサービスのマネージャを担当。
初代所長に任命された割に研究者としての実績はなく、論文は学生時代に書いたきり。他、数冊の書籍の執筆経験がある。
最近の興味の中心は、サーバの仮想化、クラスタリングなど。