Flareを使う(データ分散度合評価編)
当ブログをご覧の皆様こんにちは。さくらインターネット研究所の大久保です。 今回はFlareにおけるデータの分散度合の評価を行いましたので、そちらのご紹介をしたいと思います。
Flareのデータ分散について
以前のブログでご紹介しましたが、Flareでは、1レコード毎にパーティションと呼ばれるサーバのグループに分散します。あるレコードが格納されるパーティションは、そのキーのハッシュ値から決定されます。なお、各パーティション内にスレーブサーバを設置することでデータの冗長化を行うことができます。
概念図のみ以下再掲します。
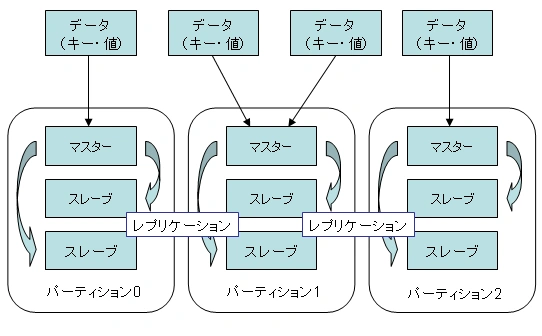
今回はこのパーティションを多数用意し、どのようにデータが分散するかを評価します。
評価条件
今回の評価条件は以下のとおりです。
サーバ構成 | インデックスサーバ | 1台 |
プロキシサーバ | 1台 | |
ストレージサーバ | 10台(10パーティション) | |
合計 | 12台 | |
テストデータ | 件数 | 100万件 |
キー名 | test00000000〜test00999999 | |
値 | 01234567890123456789012345678901234567890123456789 (50bytes) |
評価環境
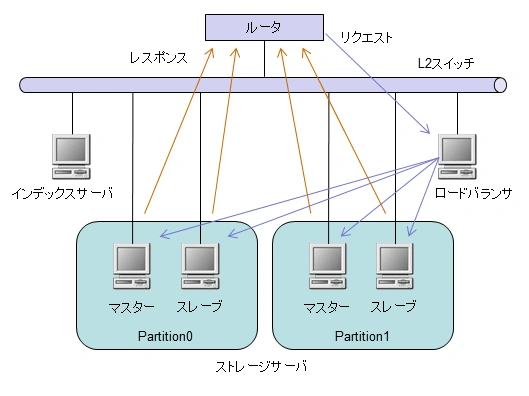
今回使用したサーバの一覧は以下のとおりです。ストレージサーバは、1台1パーティション(つまり全てマスター)になるようにしました。
サーバ番号 | IPアドレス | 役割 |
#1 | 192.168.13.41 | インデックスサーバ |
#2 | 192.168.13.42 | プロキシサーバ |
#3 | 192.168.13.43 | ストレージサーバ パーティション0 マスター |
#4 | 192.168.13.44 | ストレージサーバ パーティション1 マスター |
#5 | 192.168.13.45 | ストレージサーバ パーティション2 マスター |
#6 | 192.168.13.46 | ストレージサーバ パーティション3 マスター |
#7 | 192.168.13.47 | ストレージサーバ パーティション4 マスター |
#8 | 192.168.13.48 | ストレージサーバ パーティション5 マスター |
#9 | 192.168.13.49 | ストレージサーバ パーティション6 マスター |
#10 | 192.168.13.50 | ストレージサーバ パーティション7 マスター |
#11 | 192.168.13.51 | ストレージサーバ パーティション8 マスター |
#12 | 192.168.13.52 | ストレージサーバ パーティション9 マスター |
構成図は以下のとおりです。
サーバの設定
各サーバ上で起動するFlareの設定は以下の通りです。
- インデックスサーバの設定
data-dir = /home/admin/flare
log-facility = local0
server-name = 192.168.13.41
monitor-threshold=3
monitor-interval=1
monitor-read-timeout=1000 - ストレージサーバ、プロキシサーバの設定
※ server-nameは各サーバのIPアドレスに置き換える。
data-dir = /home/admin/flare
log-facility = local0
storage-bucket-size = 16777216
index-server-name = 192.168.13.41
server-name = 192.168.13.42
サーバを起動した後、インデックスサーバにてストレージサーバの役割設定を行います。
% telnet localhost 12120
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
node role 192.168.13.43 12121 master 1 0
node state 192.168.13.43 12121 active
node role 192.168.13.44 12121 master 1 1
node state 192.168.13.44 12121 active
node role 192.168.13.45 12121 master 1 2
node state 192.168.13.45 12121 active
node role 192.168.13.46 12121 master 1 3
node state 192.168.13.46 12121 active
node role 192.168.13.47 12121 master 1 4
node state 192.168.13.47 12121 active
node role 192.168.13.48 12121 master 1 5
node state 192.168.13.48 12121 active
node role 192.168.13.49 12121 master 1 6
node state 192.168.13.49 12121 active
node role 192.168.13.50 12121 master 1 7
node state 192.168.13.50 12121 active
node role 192.168.13.51 12121 master 1 8
node state 192.168.13.51 12121 active
node role 192.168.13.52 12121 master 1 9
node state 192.168.13.52 12121 active
役割設定を行うと以下のようになります。
$ ./flare-status.pl
role state balance partition
------------------------------------------------------------
192.168.13.42:12121 proxy active 0 -1
192.168.13.43:12121 master active 1 0
192.168.13.44:12121 master active 1 1
192.168.13.45:12121 master active 1 2
192.168.13.46:12121 master active 1 3
192.168.13.47:12121 master active 1 4
192.168.13.48:12121 master active 1 5
192.168.13.49:12121 master active 1 6
192.168.13.50:12121 master active 1 7
192.168.13.51:12121 master active 1 8
192.168.13.52:12121 master active 1 9
※ flare-status.plは、インデックスサーバのstats nodesコマンドの出力結果を整形して表示する独自のスクリプトです。
その後、プロキシサーバからテストデータを投入します。プログラムについては前回のブログをご覧下さい。
テスト結果
データの投入後、10台のストレージサーバのレコード数は以下のようになりました。
サーバ番号 | パーティション番号 | レコード数 |
#3 | 0 | 126210 |
#4 | 1 | 122471 |
#5 | 2 | 107676 |
#6 | 3 | 101425 |
#7 | 4 | 142079 |
#8 | 5 | 164229 |
#9 | 6 | 72134 |
#10 | 7 | 1101 |
#11 | 8 | 147599 |
#12 | 9 | 15076 |
合計 | 1000000 |
グラフ化すると以下のようになります。
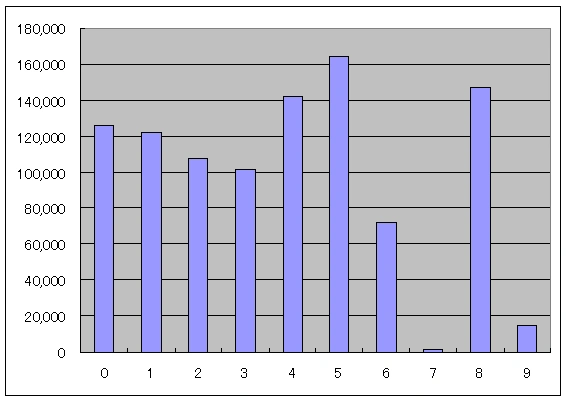
若干偏りが生じていることがわかります。
サーバを100台に増やした場合
さらにサーバを増やして合計100台の構成で試してみました。レコード数も10倍に増やしております。評価条件を以下に示します。
サーバ構成 | インデックスサーバ | 1台 |
プロキシサーバ | 1台 | |
ストレージサーバ | 98台(98パーティション) | |
合計 | 100台 | |
テストデータ | 件数 | 1000万件 |
キー名 | test00000000〜test09999999 | |
値 | 01234567890123456789012345678901234567890123456789 (50bytes) |
テストした結果、先頭の32パーティションにしかデータが格納されず、後の66パーティションには全くデータが格納されませんでした。グラフのみ以下に示しますが、データが格納された先頭の32パーティションのみを見てもかなりの偏りが生じていることがわかります。
(先頭32パーティションのみ表示)

まとめ
今回テストに使用したキーのフォーマットにも依存するのかもしれませんが、サーバが増えた場合に均等にデータが分散しないことがわかりました。データが分散しないと、ディスク容量やアクセス負荷が特定サーバに偏る可能性が高く、サーバを増やしても特定サーバがボトルネックになり、分散KVSの特長であるスケーラビリティをいかすことができません。
この事象についてFlareの作者であるグリー藤本さんにお聞きしたところ、Flareに実装されているハッシュアルゴリズムに起因するとのことで、改善をお願いしているところです。今後進展がありましたらご紹介したいと思います。